ملاحظة
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
تجميع مستندات النص باستخدام k-means#
هذا مثال يوضح كيفية استخدام واجهة برمجة التطبيقات scikit-learn لتجميع المستندات حسب الموضوعات باستخدام نهج "Bag of Words".
يتم توضيح خوارزميتين، وهما: KMeans ومتغيرها الأكثر قابلية للتطوير MiniBatchKMeans. بالإضافة إلى ذلك، يتم استخدام التحليل الدلالي الكامن لخفض الأبعاد واكتشاف الأنماط الكامنة في البيانات.
يستخدم هذا المثال طريقتين مختلفتين لاستخراج الميزات النصية: TfidfVectorizer و:class:~sklearn.feature_extraction.text.HashingVectorizer. راجع دفتر الملاحظات مقارنة بين FeatureHasher و DictVectorizer للحصول على مزيد من المعلومات حول طرق استخراج الميزات ومقارنة أوقات معالجتها.
لتحليل المستندات عبر نهج التعلم الخاضع للإشراف، راجع مثال النص البرمجي تصنيف وثائق النصوص باستخدام الميزات المتناثرة.
# المؤلفون: مطوري scikit-learn
# معرف الترخيص: BSD-3-Clause
تحميل بيانات النص#
نقوم بتحميل البيانات من The 20 newsgroups text dataset، والتي تتكون من حوالي 18,000 منشورات مجموعات الأخبار حول 20 موضوعًا. لأغراض توضيحية ولتقليل التكلفة الحسابية، نختار مجموعة فرعية من 4 مواضيع فقط، والتي تمثل حوالي 3,400 مستند. راجع المثال تصنيف وثائق النصوص باستخدام الميزات المتناثرة للحصول على الحدس حول تداخل مثل هذه الموضوعات.
لاحظ أنه، بشكل افتراضي، تحتوي عينات النص على بعض بيانات التعريف مثل
"headers"، و`"footers"` (التوقيعات) و`"quotes"` إلى منشورات أخرى. نستخدم
المعلمة remove من fetch_20newsgroups لإزالة تلك
الميزات والحصول على مشكلة تجميع أكثر منطقية.
import numpy as np
from sklearn.datasets import fetch_20newsgroups
categories = [
"alt.atheism",
"talk.religion.misc",
"comp.graphics",
"sci.space",
]
dataset = fetch_20newsgroups(
remove=("headers", "footers", "quotes"),
subset="all",
categories=categories,
shuffle=True,
random_state=42,
)
labels = dataset.target
unique_labels, category_sizes = np.unique(labels, return_counts=True)
true_k = unique_labels.shape[0]
print(f"{len(dataset.data)} documents - {true_k} categories")
3387 documents - 4 categories
تحديد جودة نتائج التجميع#
في هذا القسم، نقوم بتعريف دالة لتقييم أنابيب التجميع المختلفة باستخدام عدة مقاييس.
خوارزميات التجميع هي أساليب تعلم غير خاضعة للإشراف بشكل أساسي. ومع ذلك، نظرًا لأننا نملك تسميات الفئات لهذا المستند المحدد، فمن الممكن استخدام مقاييس التقييم التي تستفيد من معلومات "الإشراف" هذه لتقدير جودة التجميع الناتج. أمثلة على هذه المقاييس هي التالية:
التجانس، الذي يحدد مدى احتواء التجميعات على أعضاء من فئة واحدة فقط؛
الاكتمال، الذي يحدد مدى تعيين أعضاء فئة معينة إلى نفس التجميعات؛
V-measure، المتوسط التوافقي للتجانس والاكتمال؛
Rand-Index، الذي يقيس مدى تكرار أزواج نقاط البيانات بشكل متسق وفقًا لنتيجة خوارزمية التجميع وتعيين الفئة الحقيقية؛
Adjusted Rand-Index، وهو Rand-Index المعدل بحيث يكون تعيين التجميعات العشوائية له قيمة ARI تساوي 0.0 في المتوسط.
إذا لم تكن تسميات الحقيقة الأرضية معروفة، فيمكن إجراء التقييم فقط باستخدام نتائج النموذج نفسه. في هذه الحالة، يأتي معامل Silhouette Coefficient في متناول اليد. راجع تحليل السيلويت لتحديد عدد التجمعات في التجميع التجميعي KMeans لمثال حول كيفية القيام بذلك.
للحصول على مزيد من المراجع، راجع تقييم أداء التجميع.
from collections import defaultdict
from time import time
from sklearn import metrics
evaluations = []
evaluations_std = []
def fit_and_evaluate(km, X, name=None, n_runs=5):
name = km.__class__.__name__ if name is None else name
train_times = []
scores = defaultdict(list)
for seed in range(n_runs):
km.set_params(random_state=seed)
t0 = time()
km.fit(X)
train_times.append(time() - t0)
scores["Homogeneity"].append(metrics.homogeneity_score(labels, km.labels_))
scores["Completeness"].append(metrics.completeness_score(labels, km.labels_))
scores["V-measure"].append(metrics.v_measure_score(labels, km.labels_))
scores["Adjusted Rand-Index"].append(
metrics.adjusted_rand_score(labels, km.labels_)
)
scores["Silhouette Coefficient"].append(
metrics.silhouette_score(X, km.labels_, sample_size=2000)
)
train_times = np.asarray(train_times)
print(f"clustering done in {train_times.mean():.2f} ± {train_times.std():.2f} s ")
evaluation = {
"estimator": name,
"train_time": train_times.mean(),
}
evaluation_std = {
"estimator": name,
"train_time": train_times.std(),
}
for score_name, score_values in scores.items():
mean_score, std_score = np.mean(score_values), np.std(score_values)
print(f"{score_name}: {mean_score:.3f} ± {std_score:.3f}")
evaluation[score_name] = mean_score
evaluation_std[score_name] = std_score
evaluations.append(evaluation)
evaluations_std.append(evaluation_std)
التجميع باستخدام k-means على ميزات النص#
يتم استخدام طريقتين لاستخراج الميزات في هذا المثال:
TfidfVectorizerيستخدم قاموسًا في الذاكرة (قاموس Python) لتعيين الكلمات الأكثر تكرارًا إلى فهرس الميزات وبالتالي حساب مصفوفة تكرار الكلمات (مصفوفة نادرة). يتم بعد ذلك إعادة وزن تكرارات الكلمات باستخدام متجه IDF (Inverse Document Frequency) الذي تم جمعه للميزة عبر المجموعة.HashingVectorizerيقوم بتشفير تكرارات الكلمات إلى مساحة ذات أبعاد ثابتة، مع احتمالية حدوث تصادمات. يتم بعد ذلك تطبيع متجهات تكرار الكلمات بحيث يكون لها معيار l2 يساوي واحدًا (تم إسقاطها على الكرة الوحيدة الأبعاد) والتي تبدو مهمة ل k-means للعمل في مساحة ذات أبعاد عالية.
علاوة على ذلك، من الممكن معالجة الميزات المستخرجة باستخدام خفض الأبعاد. سنستكشف تأثير هذه الخيارات على جودة التجميع في ما يلي.
استخراج الميزات باستخدام TfidfVectorizer#
نقوم أولاً باختبار المقدرات باستخدام قاموس vectorizer إلى جانب
التطبيع IDF كما هو موفر بواسطة
TfidfVectorizer.
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(
max_df=0.5,
min_df=5,
stop_words="english",
)
t0 = time()
X_tfidf = vectorizer.fit_transform(dataset.data)
print(f"vectorization done in {time() - t0:.3f} s")
print(f"n_samples: {X_tfidf.shape[0]}, n_features: {X_tfidf.shape[1]}")
vectorization done in 0.480 s
n_samples: 3387, n_features: 7929
بعد تجاهل المصطلحات التي تظهر في أكثر من 50% من المستندات (كما هو محدد بواسطة
max_df=0.5) والمصطلحات التي لا تظهر في 5 مستندات على الأقل (كما هو محدد بواسطة
min_df=5)، فإن عدد المصطلحات الفريدة n_features هو حوالي
8,000. يمكننا أيضًا تحديد مدى ندرة مصفوفة X_tfidf كنسبة
من الإدخالات غير الصفرية مقسومة على العدد الإجمالي للعناصر.
print(f"{X_tfidf.nnz / np.prod(X_tfidf.shape):.3f}")
0.007
نجد أن حوالي 0.7% من إدخالات مصفوفة X_tfidf غير صفرية.
تجميع البيانات النادرة باستخدام k-means#
نظرًا لأن كل من KMeans و
MiniBatchKMeans يقومان بتحسين دالة الهدف غير المقعرة،
فإن التجميع الناتج عنهما ليس مضمونًا أن يكون الأمثل بالنسبة لبداية عشوائية معينة.
علاوة على ذلك، بالنسبة للبيانات النادرة ذات الأبعاد العالية مثل النص الذي تم تمثيله باستخدام
نهج Bag of Words، يمكن أن يقوم k-means بتهيئة المراكز على نقاط بيانات معزولة للغاية.
يمكن أن تظل هذه النقاط بياناتها الخاصة طوال الوقت.
يوضح الكود التالي كيف يمكن أن يؤدي الظاهرة السابقة في بعض الأحيان إلى تجميعات غير متوازنة للغاية، اعتمادًا على التهيئة العشوائية:
from sklearn.cluster import KMeans
for seed in range(5):
kmeans = KMeans(
n_clusters=true_k,
max_iter=100,
n_init=1,
random_state=seed,
).fit(X_tfidf)
cluster_ids, cluster_sizes = np.unique(kmeans.labels_, return_counts=True)
print(f"Number of elements assigned to each cluster: {cluster_sizes}")
print()
print(
"True number of documents in each category according to the class labels: "
f"{category_sizes}"
)
Number of elements assigned to each cluster: [ 481 675 1785 446]
Number of elements assigned to each cluster: [1689 638 480 580]
Number of elements assigned to each cluster: [ 1 1 1 3384]
Number of elements assigned to each cluster: [1887 311 332 857]
Number of elements assigned to each cluster: [ 291 673 1771 652]
True number of documents in each category according to the class labels: [799 973 987 628]
لتجنب هذه المشكلة، يمكن زيادة عدد مرات التشغيل مع
تهيئات عشوائية مستقلة n_init. في هذه الحالة، يتم اختيار التجميع مع
أفضل القصور الذاتي (دالة الهدف لـ k-means).
kmeans = KMeans(
n_clusters=true_k,
max_iter=100,
n_init=5,
)
fit_and_evaluate(kmeans, X_tfidf, name="KMeans\non tf-idf vectors")
clustering done in 0.15 ± 0.03 s
Homogeneity: 0.349 ± 0.010
Completeness: 0.398 ± 0.009
V-measure: 0.372 ± 0.009
Adjusted Rand-Index: 0.203 ± 0.017
Silhouette Coefficient: 0.007 ± 0.001
جميع مقاييس تقييم التجميع لها قيمة قصوى تبلغ 1.0 (لتجميع مثالي). القيم الأعلى أفضل. القيم القريبة من 0.0 لـ Adjusted Rand-Index تشير إلى تسمية عشوائية. لاحظ من الدرجات أعلاه أن تعيين التجميع هو بالفعل أعلى من مستوى الصدفة، ولكن الجودة الإجمالية يمكن أن تتحسن بالتأكيد.
ضع في اعتبارك أن تسميات الفئات قد لا تعكس بدقة مواضيع المستندات لذلك فإن المقاييس التي تستخدم التسميات ليست بالضرورة الأفضل لتقييم جودة أنبوب التجميع لدينا.
إجراء خفض الأبعاد باستخدام LSA#
يمكن استخدام n_init=1 طالما يتم تقليل بُعد المساحة المتجهة أولاً لجعل k-means أكثر استقرارًا. لهذا الغرض، نستخدم
TruncatedSVD، والذي يعمل على مصفوفات العد/tf-idf.
نظرًا لأن نتائج SVD غير معيارية، فإننا نعيد التطبيع لتحسين
نتيجة KMeans. استخدام SVD لخفض الأبعاد
متجهات TF-IDF غالبًا ما يُعرف باسم latent semantic
analysis (LSA) في
أدب استرجاع المعلومات وتعدين النصوص.
from sklearn.decomposition import TruncatedSVD
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import Normalizer
lsa = make_pipeline(TruncatedSVD(n_components=100), Normalizer(copy=False))
t0 = time()
X_lsa = lsa.fit_transform(X_tfidf)
explained_variance = lsa[0].explained_variance_ratio_.sum()
print(f"LSA done in {time() - t0:.3f} s")
print(f"Explained variance of the SVD step: {explained_variance * 100:.1f}%")
LSA done in 0.358 s
Explained variance of the SVD step: 18.4%
استخدام تهيئة واحدة يعني أن وقت المعالجة سيتم تقليله لكل من
KMeans و
MiniBatchKMeans.
kmeans = KMeans(
n_clusters=true_k,
max_iter=100,
n_init=1,
)
fit_and_evaluate(kmeans, X_lsa, name="KMeans\nwith LSA on tf-idf vectors")
clustering done in 0.05 ± 0.05 s
Homogeneity: 0.374 ± 0.051
Completeness: 0.446 ± 0.021
V-measure: 0.404 ± 0.035
Adjusted Rand-Index: 0.316 ± 0.041
Silhouette Coefficient: 0.030 ± 0.004
يمكننا ملاحظة أن التجميع على تمثيل LSA للمستند أسرع بشكل ملحوظ (بسبب n_init=1 وبسبب
أن بُعد مساحة ميزة LSA أصغر بكثير). علاوة على ذلك، فقد تحسنت جميع
مقاييس تقييم التجميع. نكرر التجربة مع
MiniBatchKMeans.
from sklearn.cluster import MiniBatchKMeans
minibatch_kmeans = MiniBatchKMeans(
n_clusters=true_k,
n_init=1,
init_size=1000,
batch_size=1000,
)
fit_and_evaluate(
minibatch_kmeans,
X_lsa,
name="MiniBatchKMeans\nwith LSA on tf-idf vectors",
)
clustering done in 0.08 ± 0.01 s
Homogeneity: 0.335 ± 0.071
Completeness: 0.356 ± 0.055
V-measure: 0.344 ± 0.063
Adjusted Rand-Index: 0.284 ± 0.054
Silhouette Coefficient: 0.027 ± 0.004
أهم المصطلحات لكل مجموعة#
نظرًا لأنه يمكن عكس TfidfVectorizer،
يمكننا تحديد مراكز المجموعات، والتي توفر حدسًا
للكلمات الأكثر تأثيرًا لكل مجموعة. انظر البرنامج النصي للنموذج
تصنيف وثائق النصوص باستخدام الميزات المتناثرة
لمقارنة مع الكلمات الأكثر تنبؤًا لكل فئة مستهدفة.
original_space_centroids = lsa[0].inverse_transform(kmeans.cluster_centers_)
order_centroids = original_space_centroids.argsort()[:, ::-1]
terms = vectorizer.get_feature_names_out()
for i in range(true_k):
print(f"المجموعة {i}: ", end="")
for ind in order_centroids[i, :10]:
print(f"{terms[ind]} ", end="")
print()
المجموعة 0: people don think just like say know time did does
المجموعة 1: thanks graphics image program know files file looking software edu
المجموعة 2: space launch orbit nasa shuttle earth moon like mission just
المجموعة 3: god jesus bible believe faith say christian people does christians
HashingVectorizer#
يمكن إجراء ناقل بديل باستخدام مثيل
HashingVectorizer، والذي
لا يوفر ترجيح IDF لأن هذا نموذج بدون حالة (لا يفعل أسلوب الملاءمة
شيئًا). عند الحاجة إلى ترجيح IDF، يمكن إضافته عن طريق توصيل
ناتج HashingVectorizer إلى
مثيل TfidfTransformer. في هذه
الحالة، نضيف أيضًا LSA إلى خط الأنابيب لتقليل بُعد وتناثر
مساحة المتجه المجزأة.
from sklearn.feature_extraction.text import HashingVectorizer, TfidfTransformer
lsa_vectorizer = make_pipeline(
HashingVectorizer(stop_words="english", n_features=50_000),
TfidfTransformer(),
TruncatedSVD(n_components=100, random_state=0),
Normalizer(copy=False),
)
t0 = time()
X_hashed_lsa = lsa_vectorizer.fit_transform(dataset.data)
print(f"تمت عملية النواقل في {time() - t0:.3f} s")
تمت عملية النواقل في 1.787 s
يمكن للمرء أن يلاحظ أن خطوة LSA تستغرق وقتًا طويلاً نسبيًا للملاءمة،
خاصةً مع المتجهات المجزأة. والسبب هو أن المساحة المجزأة عادةً ما تكون
كبيرة (مُعينة على n_features=50_000 في هذا المثال). يمكن للمرء محاولة
تقليل عدد الميزات على حساب وجود جزء أكبر من الميزات مع
تصادمات التجزئة كما هو موضح في دفتر ملاحظات المثال
مقارنة بين FeatureHasher و DictVectorizer.
نقوم الآن بملاءمة وتقييم مثيلي kmeans و minibatch_kmeans على هذه
البيانات المخفضة من lsa-hashed:
fit_and_evaluate(kmeans, X_hashed_lsa, name="KMeans\nمع LSA على المتجهات المجزأة")
clustering done in 0.12 ± 0.00 s
Homogeneity: 0.386 ± 0.013
Completeness: 0.429 ± 0.025
V-measure: 0.406 ± 0.019
Adjusted Rand-Index: 0.327 ± 0.019
Silhouette Coefficient: 0.029 ± 0.001
fit_and_evaluate(
minibatch_kmeans,
X_hashed_lsa,
name="MiniBatchKMeans\nمع LSA على المتجهات المجزأة",
)
clustering done in 0.09 ± 0.06 s
Homogeneity: 0.342 ± 0.060
Completeness: 0.364 ± 0.062
V-measure: 0.352 ± 0.060
Adjusted Rand-Index: 0.305 ± 0.055
Silhouette Coefficient: 0.026 ± 0.004
تؤدي كلتا الطريقتين إلى نتائج جيدة تشبه تشغيل نفس النماذج على نواقل LSA التقليدية (بدون تجزئة).
ملخص تقييم التجميع#
import matplotlib.pyplot as plt
import pandas as pd
fig, (ax0, ax1) = plt.subplots(ncols=2, figsize=(16, 6), sharey=True)
df = pd.DataFrame(evaluations[::-1]).set_index("estimator")
df_std = pd.DataFrame(evaluations_std[::-1]).set_index("estimator")
df.drop(
["train_time"],
axis="columns",
).plot.barh(ax=ax0, xerr=df_std)
ax0.set_xlabel("نتائج التجميع")
ax0.set_ylabel("")
df["train_time"].plot.barh(ax=ax1, xerr=df_std["train_time"])
ax1.set_xlabel("وقت التجميع (s)")
plt.tight_layout()
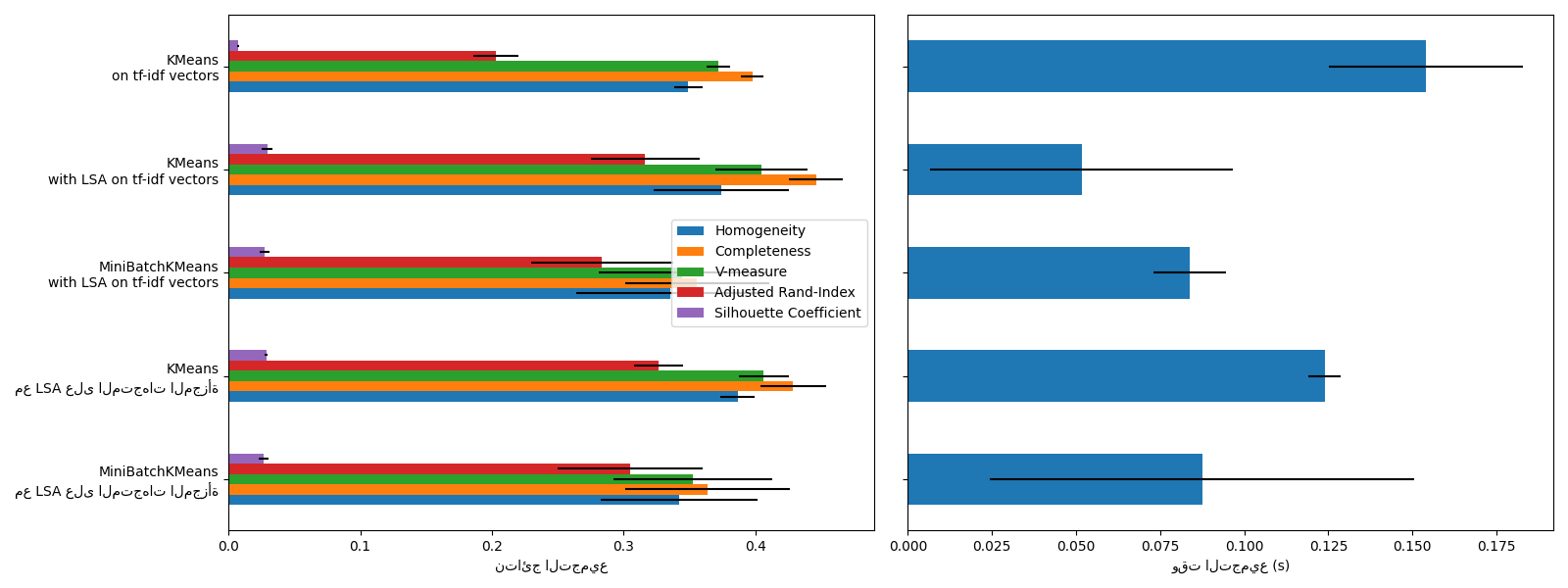
يعاني KMeans و MiniBatchKMeans
من ظاهرة تسمى لعنة الأبعاد لمجموعات البيانات
عالية الأبعاد مثل بيانات النص. هذا هو السبب في أن النتائج الإجمالية تتحسن
عند استخدام LSA. يؤدي استخدام بيانات LSA المخفضة أيضًا إلى تحسين الاستقرار
ويتطلب وقت تجميع أقل، مع مراعاة أن خطوة LSA نفسها تستغرق
وقتًا طويلاً، خاصةً مع المتجهات المجزأة.
يتم تعريف معامل Silhouette بين 0 و 1. في جميع الحالات، نحصل على قيم قريبة من 0 (حتى لو تحسنت قليلاً بعد استخدام LSA) لأن تعريفها يتطلب قياس المسافات، على عكس مقاييس التقييم الأخرى مثل مقياس V وفهرس Rand المعدل اللذين يعتمدان فقط على تعيينات المجموعات بدلاً من المسافات. لاحظ أنه، بالمعنى الدقيق للكلمة، لا ينبغي للمرء مقارنة معامل Silhouette بين مسافات ذات أبعاد مختلفة، نظرًا لمفاهيم المسافة المختلفة التي تنطوي عليها.
لا تسفر مقاييس التجانس والاكتمال، وبالتالي مقياس v، عن خط أساس فيما يتعلق بالتصنيف العشوائي: هذا يعني أنه اعتمادًا على عدد العينات والمجموعات وفئات الحقيقة الأرضية، لن ينتج عن التصنيف العشوائي تمامًا نفس القيم دائمًا. على وجه الخصوص، لن ينتج عن التصنيف العشوائي درجات صفرية، خاصةً عندما يكون عدد المجموعات كبيرًا. يمكن تجاهل هذه المشكلة بأمان عندما يكون عدد العينات أكثر من ألف ويكون عدد المجموعات أقل من 10، وهي حالة المثال الحالي. بالنسبة لأحجام العينات الأصغر أو عدد أكبر من المجموعات، من الآمن استخدام فهرس معدل مثل فهرس Rand المعدل (ARI). انظر المثال تعديل الفرصة في تقييم أداء التجميع لعرض توضيحي لتأثير التصنيف العشوائي.
يُظهر حجم أشرطة الخطأ أن MiniBatchKMeans
أقل استقرارًا من KMeans بالنسبة لمجموعة
البيانات الصغيرة نسبيًا هذه. من المثير للاهتمام استخدامه عندما يكون عدد
العينات أكبر بكثير، ولكن يمكن أن يأتي ذلك على حساب انخفاض طفيف في
جودة التجميع مقارنة بخوارزمية k-means التقليدية.
Total running time of the script: (0 minutes 9.505 seconds)
Related examples

التجميع الثنائي للمستندات باستخدام خوارزمية التجميع الطيفي المشترك
مقارنة خوارزميات التجميع K-Means و MiniBatchKMeans
