ملاحظة
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
ضبط نقطة القطع لوظيفة القرار بعد التدريب#
بمجرد تدريب مصنف ثنائي، تقوم طريقة predict بإخراج تنبؤات تسمية الفئة المقابلة لعملية عتبية إما لـ decision_function أو لـ predict_proba الإخراج. ويتم تعريف العتبة الافتراضية على أنها تقدير احتمالي لاحق يبلغ 0.5 أو درجة قرار تبلغ 0.0. ومع ذلك، قد لا تكون هذه الاستراتيجية الافتراضية مثالية للمهمة قيد التنفيذ.
يوضح هذا المثال كيفية استخدام
TunedThresholdClassifierCV لضبط عتبة القرار، اعتمادًا على مقياس الاهتمام.
# المؤلفون: مطوري scikit-learn
# معرف الترخيص: BSD-3-Clause
مجموعة بيانات مرض السكري#
لتوضيح ضبط عتبة القرار، سنستخدم مجموعة بيانات مرض السكري.
هذه المجموعة متاحة على OpenML: https://www.openml.org/d/37. نستخدم
fetch_openml الدالة لاسترجاع هذه المجموعة.
from sklearn.datasets import fetch_openml
diabetes = fetch_openml(data_id=37, as_frame=True, parser="pandas")
data, target = diabetes.data, diabetes.target
نلقي نظرة على الهدف لفهم نوع المشكلة التي نتعامل معها.
target.value_counts()
class
tested_negative 500
tested_positive 268
Name: count, dtype: int64
يمكننا أن نرى أننا نتعامل مع مشكلة تصنيف ثنائي. نظرًا لأن التصنيفات غير مشفرة على أنها 0 و 1، فإننا نجعلها صريحة بأننا نعتبر الفئة المسماة "tested_negative" كالفئة السلبية (وهي أيضًا الأكثر تكرارًا) والفئة المسماة "tested_positive" كالفئة الإيجابية:
neg_label, pos_label = target.value_counts().index
يمكننا أيضًا ملاحظة أن هذه المشكلة الثنائية غير متوازنة إلى حد ما حيث لدينا حوالي ضعف عدد العينات من الفئة السلبية مقارنة بالفئة الإيجابية. عندما يتعلق الأمر بالتقييم، يجب أن نأخذ هذا الجانب في الاعتبار لتفسير النتائج.
مصنفنا الأساسي#
نحدد نموذجًا تنبؤيًا أساسيًا يتكون من مقياس متبوعًا بمصنف الانحدار اللوجستي.
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
model = make_pipeline(StandardScaler(), LogisticRegression())
model
نقيم نموذجنا باستخدام التحقق المتقاطع. نستخدم الدقة والدقة المتوازنة للإبلاغ عن أداء نموذجنا. الدقة المتوازنة هي مقياس أقل حساسية لاختلال التوازن في الفئة وسيسمح لنا بوضع درجة الدقة في المنظور.
يسمح لنا التحقق المتقاطع بدراسة تباين عتبة القرار عبر
تقسيمات مختلفة للبيانات. ومع ذلك، فإن مجموعة البيانات صغيرة إلى حد ما وسيكون
من الضار استخدام أكثر من 5 طيات لتقييم التشتت. لذلك، نستخدم
RepeatedStratifiedKFold حيث نطبق عدة
تكرارات من التحقق المتقاطع 5-fold.
import pandas as pd
from sklearn.model_selection import RepeatedStratifiedKFold, cross_validate
scoring = ["accuracy", "balanced_accuracy"]
cv_scores = [
"train_accuracy",
"test_accuracy",
"train_balanced_accuracy",
"test_balanced_accuracy",
]
cv = RepeatedStratifiedKFold(n_splits=5, n_repeats=10, random_state=42)
cv_results_vanilla_model = pd.DataFrame(
cross_validate(
model,
data,
target,
scoring=scoring,
cv=cv,
return_train_score=True,
return_estimator=True,
)
)
cv_results_vanilla_model[cv_scores].aggregate(["mean", "std"]).T
ينجح نموذجنا التنبؤي في فهم العلاقة بين البيانات والهدف. درجات التدريب والاختبار قريبة من بعضها البعض، مما يعني أن نموذجنا التنبؤي لا يعاني من الإفراط في الملاءمة. يمكننا أيضًا ملاحظة أن الدقة المتوازنة هي أقل من الدقة، بسبب اختلال التوازن في الفئة المذكور سابقًا.
بالنسبة لهذا المصنف، نترك عتبة القرار، المستخدمة لتحويل احتمال الفئة الإيجابية إلى تنبؤ الفئة، إلى قيمتها الافتراضية: 0.5. ومع ذلك، قد لا تكون هذه العتبة مثالية. إذا كان اهتمامنا هو تعظيم الدقة المتوازنة، يجب أن نختار عتبة أخرى من شأنها أن تعظم هذا المقياس.
يسمح المقيّم TunedThresholdClassifierCV
بضبط عتبة القرار لمصنف معين بناءً على مقياس الاهتمام.
ضبط عتبة القرار#
ننشئ TunedThresholdClassifierCV ونقوم
بتهيئته لتعظيم الدقة المتوازنة. نقيم النموذج باستخدام نفس
استراتيجية التحقق المتقاطع كما في السابق.
from sklearn.model_selection import TunedThresholdClassifierCV
tuned_model = TunedThresholdClassifierCV(estimator=model, scoring="balanced_accuracy")
cv_results_tuned_model = pd.DataFrame(
cross_validate(
tuned_model,
data,
target,
scoring=scoring,
cv=cv,
return_train_score=True,
return_estimator=True,
)
)
cv_results_tuned_model[cv_scores].aggregate(["mean", "std"]).T
بالمقارنة مع النموذج الأساسي، نلاحظ أن درجة الدقة المتوازنة زادت. بالطبع، يأتي ذلك على حساب انخفاض درجة الدقة. هذا يعني أن نموذجنا أصبح الآن أكثر حساسية للفئة الإيجابية ولكنه يرتكب أخطاء أكثر على الفئة السلبية.
ومع ذلك، من المهم ملاحظة أن هذا النموذج التنبؤي المضبوط هو داخليًا نفس النموذج الأساسي: لديهم نفس المعاملات المناسبة.
import matplotlib.pyplot as plt
vanilla_model_coef = pd.DataFrame(
[est[-1].coef_.ravel() for est in cv_results_vanilla_model["estimator"]],
columns=diabetes.feature_names,
)
tuned_model_coef = pd.DataFrame(
[est.estimator_[-1].coef_.ravel() for est in cv_results_tuned_model["estimator"]],
columns=diabetes.feature_names,
)
fig, ax = plt.subplots(ncols=2, figsize=(12, 4), sharex=True, sharey=True)
vanilla_model_coef.boxplot(ax=ax[0])
ax[0].set_ylabel("قيمة المعامل")
ax[0].set_title("النموذج الأساسي")
tuned_model_coef.boxplot(ax=ax[1])
ax[1].set_title("النموذج المضبوط")
_ = fig.suptitle("معاملات النماذج التنبؤية")
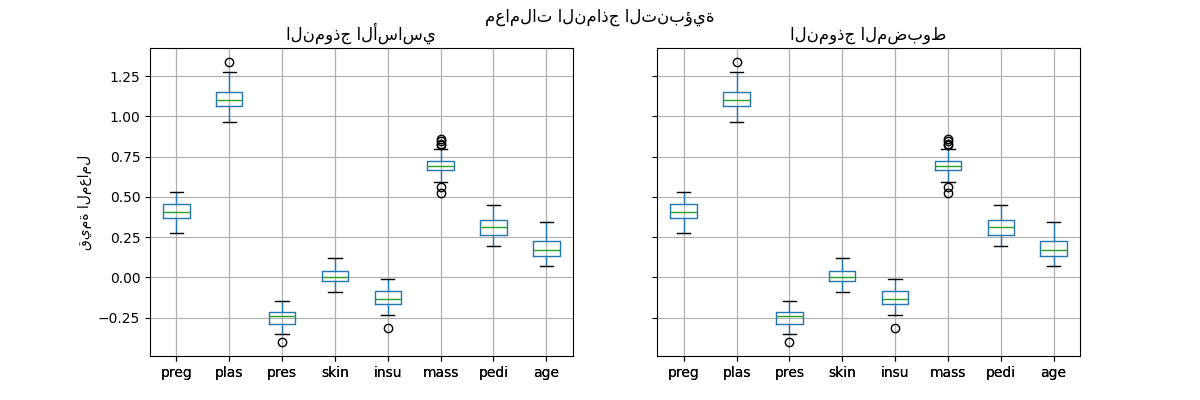
تم تغيير عتبة القرار لكل نموذج فقط أثناء التحقق المتقاطع.
decision_threshold = pd.Series(
[est.best_threshold_ for est in cv_results_tuned_model["estimator"]],
)
ax = decision_threshold.plot.kde()
ax.axvline(
decision_threshold.mean(),
color="k",
linestyle="--",
label=f"عتبة القرار المتوسطة: {decision_threshold.mean():.2f}",
)
ax.set_xlabel("عتبة القرار")
ax.legend(loc="upper right")
_ = ax.set_title(
"توزيع عتبة القرار \nعبر طيات التحقق المتقاطع المختلفة"
)
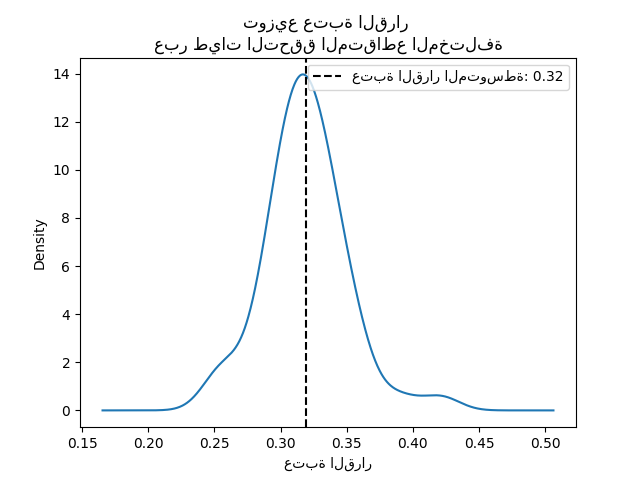
في المتوسط، تعظم عتبة القرار التي تبلغ حوالي 0.32 الدقة المتوازنة، والتي تختلف عن عتبة القرار الافتراضية البالغة 0.5. وبالتالي، فإن ضبط عتبة القرار مهم بشكل خاص عندما يتم استخدام ناتج النموذج التنبؤي لاتخاذ القرارات. بالإضافة إلى ذلك، يجب اختيار المقياس المستخدم لضبط عتبة القرار بعناية. هنا، استخدمنا الدقة المتوازنة ولكن قد لا يكون المقياس الأنسب للمشكلة قيد التنفيذ. عادةً ما يعتمد اختيار المقياس "الصحيح" على المشكلة وقد يتطلب بعض المعرفة بالمجال. راجع المثال المعنون، ضبط عتبة القرار للتعلم الحساس للتكلفة، لمزيد من التفاصيل.
Total running time of the script: (0 minutes 39.766 seconds)
Related examples
أبرز الميزات الجديدة في الإصدار 1.5 من scikit-learn
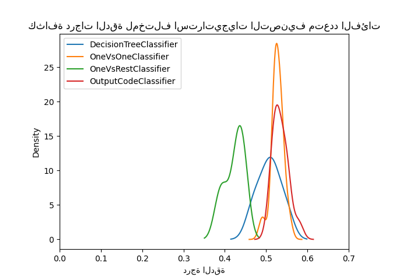
نظرة عامة على الميتا-مقدّرات التدريب متعدد التصنيفات