ملاحظة
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
التجميع الثنائي للمستندات باستخدام خوارزمية التجميع الطيفي المشترك#
هذا المثال يوضح خوارزمية التجميع الطيفي المشترك على مجموعة بيانات مجموعات الأخبار العشرين. تم استبعاد الفئة 'comp.os.ms-windows.misc' لأنها تحتوي على العديد من المنشورات التي لا تحتوي إلا على بيانات.
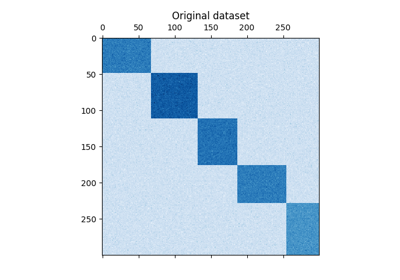
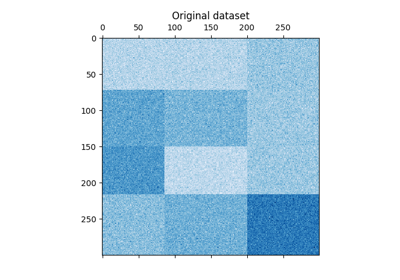
المنشورات المتجهة TF-IDF تشكل مصفوفة تكرار الكلمات، والتي يتم بعد ذلك تجمعها باستخدام خوارزمية Dhillon's Spectral Co-Clustering. تشير مجموعات التجميع الفرعية للوثائق-الكلمات الناتجة إلى مجموعات فرعية من الكلمات المستخدمة بشكل متكرر أكثر في تلك المستندات الفرعية.
بالنسبة لبعض أفضل مجموعات التجميع الفرعية، يتم طباعة فئات المستندات الأكثر شيوعًا وأهم عشر كلمات لها. يتم تحديد أفضل مجموعات التجميع الفرعية من خلال قطعها المعيارية. يتم تحديد أفضل الكلمات من خلال مقارنة مجموعها داخل وخارج مجموعة التجميع الفرعية.
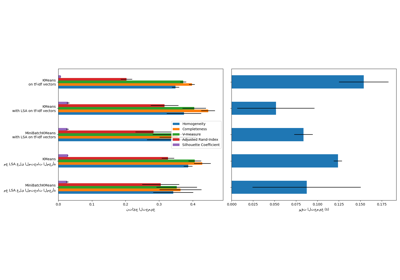
لمقارنة، يتم أيضًا تجميع المستندات باستخدام MiniBatchKMeans. تحقق مجموعات المستندات المشتقة من مجموعات التجميع الفرعية قياس V أفضل من المجموعات التي وجدها MiniBatchKMeans.
Vectorizing...
Coclustering...
Done in 1.69s. V-measure: 0.4454
MiniBatchKMeans...
Done in 1.56s. V-measure: 0.2964
Best biclusters:
----------------
bicluster 0 : 1161 documents, 3165 words
categories : 29% talk.politics.mideast, 27% soc.religion.christian, 26% alt.atheism
words : god, jesus, christians, atheists, morality, kent, belief, sin, objective, resurrection
bicluster 1 : 1653 documents, 4015 words
categories : 28% talk.politics.guns, 19% sci.med, 15% soc.religion.christian
words : gun, guns, geb, banks, firearms, gordon, dyer, amendment, pitt, cdt
bicluster 2 : 2239 documents, 2805 words
categories : 18% comp.sys.mac.hardware, 16% comp.sys.ibm.pc.hardware, 15% comp.graphics
words : voltage, dsp, shipping, circuit, stereo, receiver, compression, processing, circuits, supply
bicluster 3 : 1732 documents, 2617 words
categories : 27% rec.motorcycles, 23% rec.autos, 13% misc.forsale
words : bike, car, dod, ride, engine, motorcycle, honda, bikes, behanna, helmet
bicluster 4 : 12 documents, 149 words
categories : 100% rec.sport.hockey
words : scorer, unassisted, reichel, semak, sweeney, kovalenko, ricci, audette, momesso, nedved
# المؤلفون: مطوري سكايلرن
# معرف الترخيص: BSD-3-Clause
from collections import Counter
from time import time
import numpy as np
from sklearn.cluster import MiniBatchKMeans, SpectralCoclustering
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.cluster import v_measure_score
def number_normalizer(tokens):
"""Map all numeric tokens to a placeholder.
For many applications, tokens that begin with a number are not directly
useful, but the fact that such a token exists can be relevant. By applying
this form of dimensionality reduction, some methods may perform better.
"""
return ("#NUMBER" if token[0].isdigit() else token for token in tokens)
class NumberNormalizingVectorizer(TfidfVectorizer):
def build_tokenizer(self):
tokenize = super().build_tokenizer()
return lambda doc: list(number_normalizer(tokenize(doc)))
# استبعاد 'comp.os.ms-windows.misc'
categories = [
"alt.atheism",
"comp.graphics",
"comp.sys.ibm.pc.hardware",
"comp.sys.mac.hardware",
"comp.windows.x",
"misc.forsale",
"rec.autos",
"rec.motorcycles",
"rec.sport.baseball",
"rec.sport.hockey",
"sci.crypt",
"sci.electronics",
"sci.med",
"sci.space",
"soc.religion.christian",
"talk.politics.guns",
"talk.politics.mideast",
"talk.religion.misc",
]
newsgroups = fetch_20newsgroups(categories=categories)
y_true = newsgroups.target
vectorizer = NumberNormalizingVectorizer(stop_words="english", min_df=5)
cocluster = SpectralCoclustering(
n_clusters=len(categories), svd_method="arpack", random_state=0
)
kmeans = MiniBatchKMeans(
n_clusters=len(categories), batch_size=20000, random_state=0, n_init=3
)
print("Vectorizing...")
X = vectorizer.fit_transform(newsgroups.data)
print("Coclustering...")
start_time = time()
cocluster.fit(X)
y_cocluster = cocluster.row_labels_
print(
f"Done in {time() - start_time:.2f}s. V-measure: \
{v_measure_score(y_cocluster, y_true):.4f}"
)
print("MiniBatchKMeans...")
start_time = time()
y_kmeans = kmeans.fit_predict(X)
print(
f"Done in {time() - start_time:.2f}s. V-measure: \
{v_measure_score(y_kmeans, y_true):.4f}"
)
feature_names = vectorizer.get_feature_names_out()
document_names = list(newsgroups.target_names[i] for i in newsgroups.target)
def bicluster_ncut(i):
rows, cols = cocluster.get_indices(i)
if not (np.any(rows) and np.any(cols)):
import sys
return sys.float_info.max
row_complement = np.nonzero(np.logical_not(cocluster.rows_[i]))[0]
col_complement = np.nonzero(np.logical_not(cocluster.columns_[i]))[0]
# Note: the following is identical to X[rows[:, np.newaxis],
# cols].sum() but much faster in scipy <= 0.16
weight = X[rows][:, cols].sum()
cut = X[row_complement][:, cols].sum() + X[rows][:, col_complement].sum()
return cut / weight
bicluster_ncuts = list(bicluster_ncut(i)
for i in range(len(newsgroups.target_names)))
best_idx = np.argsort(bicluster_ncuts)[:5]
print()
print("Best biclusters:")
print("----------------")
for idx, cluster in enumerate(best_idx):
n_rows, n_cols = cocluster.get_shape(cluster)
cluster_docs, cluster_words = cocluster.get_indices(cluster)
if not len(cluster_docs) or not len(cluster_words):
continue
# categories
counter = Counter(document_names[doc] for doc in cluster_docs)
cat_string = ", ".join(
f"{(c / n_rows * 100):.0f}% {name}" for name, c in counter.most_common(3)
)
# words
out_of_cluster_docs = cocluster.row_labels_ != cluster
out_of_cluster_docs = np.where(out_of_cluster_docs)[0]
word_col = X[:, cluster_words]
word_scores = np.array(
word_col[cluster_docs, :].sum(axis=0)
- word_col[out_of_cluster_docs, :].sum(axis=0)
)
word_scores = word_scores.ravel()
important_words = list(
feature_names[cluster_words[i]] for i in word_scores.argsort()[:-11:-1]
)
print(f"bicluster {idx} : {n_rows} documents, {n_cols} words")
print(f"categories : {cat_string}")
print(f"words : {', '.join(important_words)}\n")
Total running time of the script: (0 minutes 6.334 seconds)
Related examples