ملاحظة
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
أبرز ميزات الإصدار 1.3 من scikit-learn#
يسعدنا الإعلان عن إصدار scikit-learn 1.3! تم إصلاح العديد من الأخطاء وإجراء تحسينات، بالإضافة إلى بعض الميزات الرئيسية الجديدة. نستعرض أدناه بعض الميزات الرئيسية لهذا الإصدار. للاطلاع على قائمة شاملة بجميع التغييرات، يرجى الرجوع إلى ملاحظات الإصدار.
لتثبيت أحدث إصدار (باستخدام pip):
pip install --upgrade scikit-learn
أو باستخدام conda:
conda install -c conda-forge scikit-learn
توجيه البيانات الوصفية#
نحن بصدد تقديم طريقة جديدة لتوجيه البيانات الوصفية مثل
sample_weight في جميع أنحاء قاعدة الكود، والتي ستؤثر على كيفية
توجيه البيانات الوصفية في المُقدرات الفوقية مثل pipeline.Pipeline
و model_selection.GridSearchCV. على الرغم من أن البنية التحتية
لهذه الميزة موجودة بالفعل في هذا الإصدار، إلا أن العمل لا يزال جارياً
ولا تدعم جميع المُقدرات الفوقية هذه الميزة الجديدة. يمكنك قراءة
المزيد عن هذه الميزة في دليل المستخدم لتوجيه البيانات الوصفية. يرجى ملاحظة أن هذه الميزة لا تزال قيد التطوير
ولم يتم تنفيذها لمعظم المُقدرات الفوقية.
يمكن لمطوري الجهات الخارجية البدء بالفعل في دمج هذه الميزة في المُقدرات الفوقية الخاصة بهم. لمزيد من التفاصيل، راجع دليل المطور لتوجيه البيانات الوصفية.
HDBSCAN: التجميع القائم على الكثافة الهرمية#
تم استضافة cluster.HDBSCAN في مستودع scikit-learn-contrib
في الأصل، وتم اعتماده الآن في scikit-learn. يفتقد بعض الميزات من
التنفيذ الأصلي والتي سيتم إضافتها في الإصدارات المستقبلية.
من خلال تنفيذ نسخة معدلة من cluster.DBSCAN على عدة قيم
epsilon في نفس الوقت، يقوم cluster.HDBSCAN باكتشاف مجموعات
ذات كثافات متنوعة، مما يجعله أكثر مرونة في اختيار المعلمات
مقارنة بـ cluster.DBSCAN.
لمزيد من التفاصيل، راجع دليل المستخدم.
import numpy as np
from sklearn.cluster import HDBSCAN
from sklearn.datasets import load_digits
from sklearn.metrics import v_measure_score
X, true_labels = load_digits(return_X_y=True)
print(f"عدد الأرقام: {len(np.unique(true_labels))}")
hdbscan = HDBSCAN(min_cluster_size=15).fit(X)
non_noisy_labels = hdbscan.labels_[hdbscan.labels_ != -1]
print(f"عدد المجموعات المكتشفة: {len(np.unique(non_noisy_labels))}")
print(v_measure_score(true_labels[hdbscan.labels_ != -1], non_noisy_labels))
عدد الأرقام: 10
عدد المجموعات المكتشفة: 11
0.969526722382904
TargetEncoder: استراتيجية ترميز فئات جديدة#
مناسب للفئات ذات الكاردينالية العالية،
preprocessing.TargetEncoder يقوم بترميز الفئات بناءً على تقدير
منكمش للقيم المتوسطة للهدف للملاحظات التي تنتمي إلى تلك الفئة.
لمزيد من التفاصيل، راجع دليل المستخدم.
import numpy as np
from sklearn.preprocessing import TargetEncoder
X = np.array([["cat"] * 30 + ["dog"] * 20 + ["snake"] * 38], dtype=object).T
y = [90.3] * 30 + [20.4] * 20 + [21.2] * 38
enc = TargetEncoder(random_state=0)
X_trans = enc.fit_transform(X, y)
enc.encodings_
[array([90.3, 20.4, 21.2])]
دعم القيم المفقودة في أشجار القرار#
تدعم الفئات tree.DecisionTreeClassifier و
tree.DecisionTreeRegressor الآن القيم المفقودة. بالنسبة لكل عتبة
محتملة على البيانات غير المفقودة، سيقوم المقسم بتقييم التقسيم مع
جميع القيم المفقودة التي تذهب إلى العقدة اليسرى أو العقدة اليمنى.
لمزيد من التفاصيل، راجع دليل المستخدم
أو راجع الميزات في أشجار التعزيز المتدرج للهيستوغرام
لمثال على حالة استخدام هذه الميزة في
HistGradientBoostingRegressor.
import numpy as np
from sklearn.tree import DecisionTreeClassifier
X = np.array([0, 1, 6, np.nan]).reshape(-1, 1)
y = [0, 0, 1, 1]
tree = DecisionTreeClassifier(random_state=0).fit(X, y)
tree.predict(X)
array([0, 0, 1, 1])
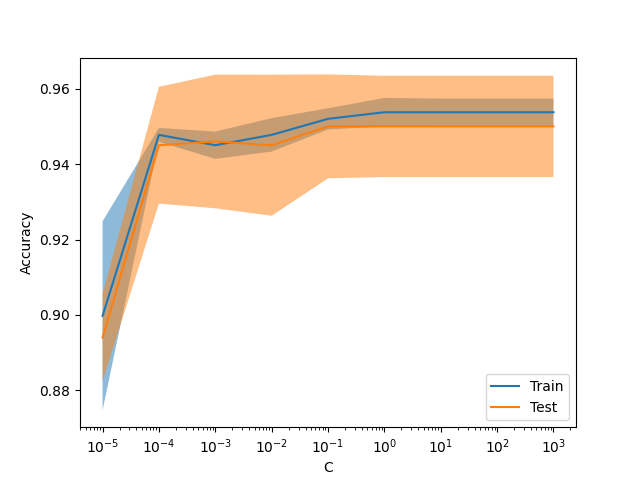
عرض جديد ValidationCurveDisplay#
model_selection.ValidationCurveDisplay متاح الآن لرسم النتائج
من model_selection.validation_curve.
from sklearn.datasets import make_classification
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import ValidationCurveDisplay
X, y = make_classification(1000, 10, random_state=0)
_ = ValidationCurveDisplay.from_estimator(
LogisticRegression(),
X,
y,
param_name="C",
param_range=np.geomspace(1e-5, 1e3, num=9),
score_type="both",
score_name="Accuracy",
)
خسارة Gamma للتعزيز التدريجي#
تدعم الفئة ensemble.HistGradientBoostingRegressor
دالة خسارة الانحراف Gamma عبر loss="gamma". هذه دالة خسارة مفيدة
لنمذجة الأهداف الإيجابية الصارمة مع توزيع منحرف إلى اليمين.
import numpy as np
from sklearn.model_selection import cross_val_score
from sklearn.datasets import make_low_rank_matrix
from sklearn.ensemble import HistGradientBoostingRegressor
n_samples, n_features = 500, 10
rng = np.random.RandomState(0)
X = make_low_rank_matrix(n_samples, n_features, random_state=rng)
coef = rng.uniform(low=-10, high=20, size=n_features)
y = rng.gamma(shape=2, scale=np.exp(X @ coef) / 2)
gbdt = HistGradientBoostingRegressor(loss="gamma")
cross_val_score(gbdt, X, y).mean()
np.float64(0.46858513287221665)
تجميع الفئات غير المتكررة في OrdinalEncoder#
على غرار preprocessing.OneHotEncoder، تدعم الفئة
preprocessing.OrdinalEncoder الآن تجميع الفئات غير المتكررة
في ناتج واحد لكل ميزة. المعاملات لتمكين تجميع الفئات غير المتكررة
هي min_frequency و max_categories.
راجع دليل المستخدم لمزيد من التفاصيل.
from sklearn.preprocessing import OrdinalEncoder
import numpy as np
X = np.array(
[["dog"] * 5 + ["cat"] * 20 + ["rabbit"] * 10 + ["snake"] * 3], dtype=object
).T
enc = OrdinalEncoder(min_frequency=6).fit(X)
enc.infrequent_categories_
[array(['dog', 'snake'], dtype=object)]
Total running time of the script: (0 minutes 1.799 seconds)
Related examples