ملاحظة
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
تصنيف أقرب الجيران#
هذا المثال يوضح كيفية استخدام KNeighborsClassifier.
نقوم بتدريب مصنف مثل هذا على مجموعة بيانات الزهرة النرجسية ونلاحظ الفرق في حدود القرار التي تم الحصول عليها فيما يتعلق بمعلمة weights.
# المؤلفون: مطوري سكايلرن
# معرف الترخيص: BSD-3-Clause
تحميل البيانات#
في هذا المثال، نستخدم مجموعة بيانات الزهرة النرجسية. نقوم بتقسيم البيانات إلى مجموعة تدريب واختبار.
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
iris = load_iris(as_frame=True)
X = iris.data[["sepal length (cm)", "sepal width (cm)"]]
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=0)
مصنف أقرب الجيران#
نريد استخدام مصنف أقرب الجيران مع مراعاة حي من 11 نقطة بيانات. نظرًا لأن نموذج أقرب الجيران لدينا يستخدم المسافة الإقليدية للعثور على الجيران الأقرب، فمن المهم بالتالي قياس البيانات مسبقًا. يرجى الرجوع إلى المثال المعنون أهمية معايرة الميزات للحصول على معلومات أكثر تفصيلاً.
لذلك، نستخدم Pipeline لربط مقياس قبل استخدام
المصنف الخاص بنا.
from sklearn.neighbors import KNeighborsClassifier
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
clf = Pipeline(
steps=[("scaler", StandardScaler()), ("knn", KNeighborsClassifier(n_neighbors=11))]
)
حدود القرار#
الآن، نقوم بتدريب مصنفين مع قيم مختلفة لمعلمة
weights. نقوم برسم حدود القرار لكل مصنف بالإضافة إلى مجموعة البيانات الأصلية لملاحظة الفرق.
import matplotlib.pyplot as plt
from sklearn.inspection import DecisionBoundaryDisplay
_, axs = plt.subplots(ncols=2, figsize=(12, 5))
for ax, weights in zip(axs, ("uniform", "distance")):
clf.set_params(knn__weights=weights).fit(X_train, y_train)
disp = DecisionBoundaryDisplay.from_estimator(
clf,
X_test,
response_method="predict",
plot_method="pcolormesh",
xlabel=iris.feature_names[0],
ylabel=iris.feature_names[1],
shading="auto",
alpha=0.5,
ax=ax,
)
scatter = disp.ax_.scatter(X.iloc[:, 0], X.iloc[:, 1], c=y, edgecolors="k")
disp.ax_.legend(
scatter.legend_elements()[0],
iris.target_names,
loc="lower left",
title="Classes",
)
_ = disp.ax_.set_title(
f"3-Class classification\n(k={clf[-1].n_neighbors}, weights={weights!r})"
)
plt.show()
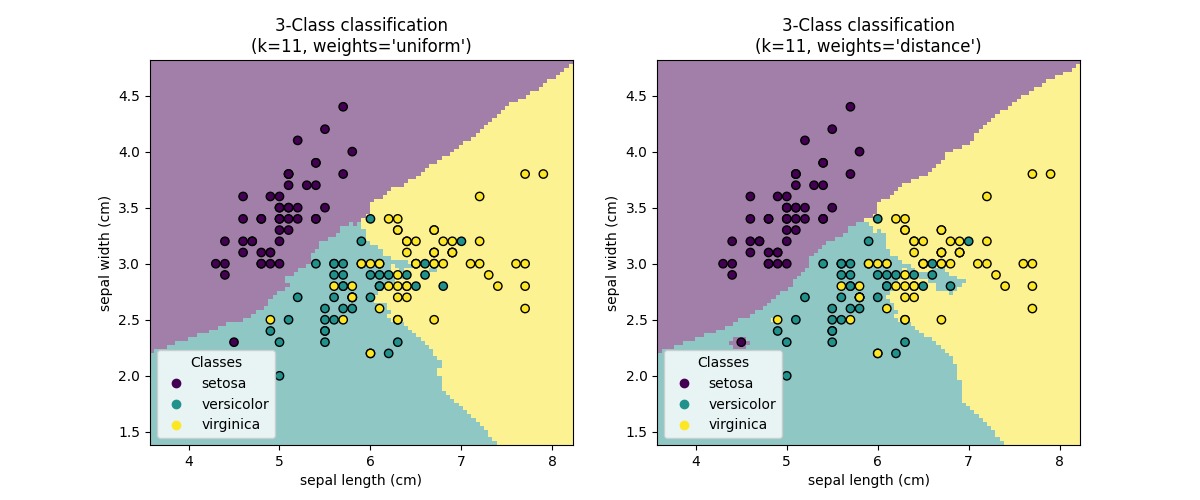
الخلاصة#
نلاحظ أن لمعلمة weights تأثير على حدود القرار. عندما
weights="unifom" سيكون لجميع الجيران الأقرب نفس التأثير على القرار.
في حين عندما weights="distance" يكون الوزن المعطى لكل جار يتناسب
مع العكس لمسافة ذلك الجار من نقطة الاستعلام.
في بعض الحالات، قد يؤدي أخذ المسافة في الاعتبار إلى تحسين النموذج.
Total running time of the script: (0 minutes 0.753 seconds)
Related examples
رسم سطح القرار لأشجار القرار المدربة على مجموعة بيانات الزهرة الآرغوانية