ملاحظة
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
نظرة عامة على الميتا-مقدّرات التدريب متعدد التصنيفات#
في هذا المثال، نناقش مشكلة التصنيف عندما تكون المتغيرات المستهدفة مكونة من أكثر من فئتين. يُطلق على ذلك التصنيف متعدد الفئات.
في مكتبة ساي كيت ليرن، تدعم جميع المُقدّرات التصنيف متعدد الفئات بشكل افتراضي: حيث تم تنفيذ الاستراتيجية الأكثر ملاءمة للمستخدم النهائي. تُنفذ وحدة sklearn.multiclass استراتيجيات مختلفة يمكن استخدامها للتجربة أو لتطوير مُقدّرات تابعة لطرف ثالث تدعم التصنيف الثنائي فقط.
تتضمن وحدة sklearn.multiclass استراتيجيات OvO/OvR المستخدمة لتدريب مُقدّر متعدد التصنيفات من خلال ملاءمة مجموعة من المُقدّرات الثنائية (المُقدّرات الفوقية OneVsOneClassifier و OneVsRestClassifier). سيقوم هذا المثال بمراجعة هذه الاستراتيجيات.
# المؤلفون: مطوّرو ساي كيت ليرن
# معرف الترخيص: BSD-3-Clause
مجموعة بيانات الخميرة من UCI#
في هذا المثال، نستخدم مجموعة بيانات UCI [1]، والتي يُشار إليها عمومًا بمجموعة بيانات الخميرة. نستخدم الدالة sklearn.datasets.fetch_openml لتحميل المجموعة من OpenML.
from sklearn.datasets import fetch_openml
X, y = fetch_openml(data_id=181, as_frame=True, return_X_y=True)
لمعرفة نوع مشكلة علم البيانات التي نتعامل معها، يمكننا التحقق من الهدف الذي نريد بناء نموذج تنبؤي له.
y.value_counts().sort_index()
class_protein_localization
CYT 463
ERL 5
EXC 35
ME1 44
ME2 51
ME3 163
MIT 244
NUC 429
POX 20
VAC 30
Name: count, dtype: int64
نرى أن الهدف منفصل ويتكون من 10 فئات. لذلك، نتعامل مع مشكلة التصنيف متعدد الفئات.
مقارنة الاستراتيجيات#
في التجربة التالية، نستخدم
DecisionTreeClassifier و
RepeatedStratifiedKFold للتحقق المتقاطع
مع 3 تقسيمات و5 تكرارات.
نقارن الاستراتيجيات التالية:
:class:~sklearn.tree.DecisionTreeClassifier يمكنه التعامل مع التصنيف متعدد الفئات بدون الحاجة إلى أي تعديلات خاصة. يعمل عن طريق تقسيم بيانات التدريب إلى مجموعات فرعية أصغر والتركيز على الفئة الأكثر شيوعًا في كل مجموعة فرعية. من خلال تكرار هذه العملية، يمكن للنموذج تصنيف بيانات الإدخال بدقة إلى فئات متعددة مختلفة.
OneVsOneClassifierيدرب مجموعة من المُقدّرات الثنائية حيث يتم تدريب كل مُقدّر للتمييز بين فئتين.OneVsRestClassifier: يدرب مجموعة من المُقدّرات الثنائية حيث يتم تدريب كل مُقدّر للتمييز بين فئة واحدة وبقية الفئات.OutputCodeClassifier: يدرب مجموعة من المُقدّرات الثنائية حيث يتم تدريب كل مُقدّر للتمييز بين مجموعة من الفئات من بقية الفئات. يتم تحديد مجموعة الفئات بواسطة كتاب الشفرات، والذي يتم إنشاؤه بشكل عشوائي في ساي كيت ليرن. تعرض هذه الطريقة معاملcode_sizeللتحكم في حجم كتاب الشفرات. نقوم بضبطه فوق واحد لأننا غير مهتمين بضغط تمثيل الفئة.
import pandas as pd
from sklearn.model_selection import RepeatedStratifiedKFold, cross_validate
from sklearn.multiclass import (
OneVsOneClassifier,
OneVsRestClassifier,
OutputCodeClassifier,
)
from sklearn.tree import DecisionTreeClassifier
cv = RepeatedStratifiedKFold(n_splits=3, n_repeats=5, random_state=0)
tree = DecisionTreeClassifier(random_state=0)
ovo_tree = OneVsOneClassifier(tree)
ovr_tree = OneVsRestClassifier(tree)
ecoc = OutputCodeClassifier(tree, code_size=2)
cv_results_tree = cross_validate(tree, X, y, cv=cv, n_jobs=2)
cv_results_ovo = cross_validate(ovo_tree, X, y, cv=cv, n_jobs=2)
cv_results_ovr = cross_validate(ovr_tree, X, y, cv=cv, n_jobs=2)
cv_results_ecoc = cross_validate(ecoc, X, y, cv=cv, n_jobs=2)
يمكننا الآن مقارنة الأداء الإحصائي للاستراتيجيات المختلفة. نرسم توزيع الدرجات لمختلف الاستراتيجيات.
from matplotlib import pyplot as plt
scores = pd.DataFrame(
{
"DecisionTreeClassifier": cv_results_tree["test_score"],
"OneVsOneClassifier": cv_results_ovo["test_score"],
"OneVsRestClassifier": cv_results_ovr["test_score"],
"OutputCodeClassifier": cv_results_ecoc["test_score"],
}
)
ax = scores.plot.kde(legend=True)
ax.set_xlabel("درجة الدقة")
ax.set_xlim([0, 0.7])
_ = ax.set_title(
"كثافة درجات الدقة لمختلف استراتيجيات التصنيف متعدد الفئات"
)
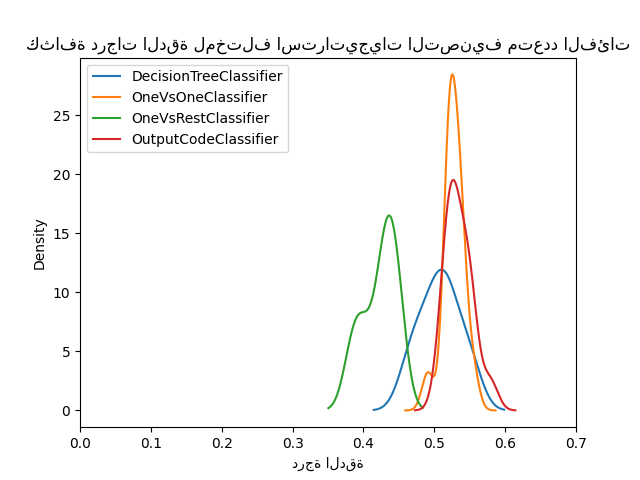
للوهلة الأولى، يمكننا أن نرى أن الاستراتيجية المدمجة لمُقدّر شجرة القرار تعمل بشكل جيد جدًا. تعمل استراتيجية واحد مقابل واحد واستراتيجية تصحيح الأخطاء بشكل أفضل. ومع ذلك، فإن استراتيجية واحد مقابل البقية لا تعمل بشكل جيد مثل الاستراتيجيات الأخرى.
في الواقع، تُعيد هذه النتائج شيئًا تم الإبلاغ عنه في الأدبيات كما في [2]. ومع ذلك، القصة ليست بسيطة كما تبدو.
أهمية البحث عن المعاملات الفائقة#
تم إظهار لاحقًا في [3] أن استراتيجيات التصنيف متعدد الفئات ستظهر درجات مماثلة إذا تم تحسين المعاملات الفائقة للمُقدّرات الأساسية أولاً.
هنا نحاول إعادة إنتاج مثل هذه النتيجة من خلال تحسين عمق شجرة القرار الأساسية على الأقل.
from sklearn.model_selection import GridSearchCV
param_grid = {"max_depth": [3, 5, 8]}
tree_optimized = GridSearchCV(tree, param_grid=param_grid, cv=3)
ovo_tree = OneVsOneClassifier(tree_optimized)
ovr_tree = OneVsRestClassifier(tree_optimized)
ecoc = OutputCodeClassifier(tree_optimized, code_size=2)
cv_results_tree = cross_validate(tree_optimized, X, y, cv=cv, n_jobs=2)
cv_results_ovo = cross_validate(ovo_tree, X, y, cv=cv, n_jobs=2)
cv_results_ovr = cross_validate(ovr_tree, X, y, cv=cv, n_jobs=2)
cv_results_ecoc = cross_validate(ecoc, X, y, cv=cv, n_jobs=2)
scores = pd.DataFrame(
{
"DecisionTreeClassifier": cv_results_tree["test_score"],
"OneVsOneClassifier": cv_results_ovo["test_score"],
"OneVsRestClassifier": cv_results_ovr["test_score"],
"OutputCodeClassifier": cv_results_ecoc["test_score"],
}
)
ax = scores.plot.kde(legend=True)
ax.set_xlabel("درجة الدقة")
ax.set_xlim([0, 0.7])
_ = ax.set_title(
"كثافة درجات الدقة لمختلف استراتيجيات التصنيف متعدد الفئات"
)
plt.show()
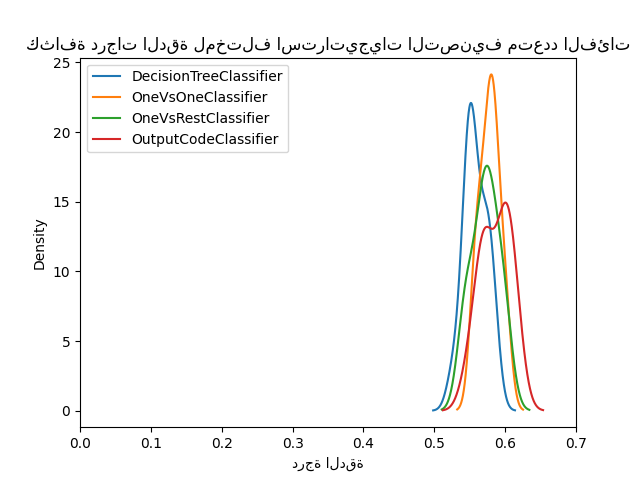
يمكننا أن نرى أنه بمجرد تحسين المعاملات الفائقة، فإن جميع استراتيجيات التصنيف متعدد الفئات لها أداء مماثل كما هو موضح في [3].
الخاتمة#
يمكننا الحصول على بعض الحدس وراء هذه النتائج.
أولاً، السبب الذي يجعل استراتيجية واحد مقابل واحد وتصحيح الأخطاء تتفوق على شجرة القرار عندما لا يتم تحسين المعاملات الفائقة يعتمد على حقيقة أنها تجمع عددًا أكبر من المُقدّرات. يؤدي التجميع إلى تحسين أداء التعميم. هذا مشابه إلى حد ما لسبب أداء مُقدّر التجميع بشكل أفضل من شجرة قرار واحدة إذا لم يتم الاهتمام بتحسين المعاملات الفائقة.
بعد ذلك، نرى أهمية تحسين المعاملات الفائقة. في الواقع، يجب استكشافها بانتظام عند تطوير نماذج تنبؤية حتى إذا كانت تقنيات مثل التجميع تساعد على تقليل هذا التأثير.
أخيرًا، من المهم التذكير بأن المُقدّرات في ساي كيت ليرن يتم تطويرها مع استراتيجية محددة للتعامل مع التصنيف متعدد الفئات بشكل افتراضي. لذلك، بالنسبة لهذه المُقدّرات، لا توجد حاجة لاستخدام استراتيجيات مختلفة. هذه الاستراتيجيات مفيدة بشكل أساسي للمُقدّرات التابعة لطرف ثالث والتي تدعم التصنيف الثنائي فقط. في جميع الحالات، نُظهر أيضًا أنه يجب تحسين المعاملات الفائقة.
المراجع#
Total running time of the script: (0 minutes 29.029 seconds)
Related examples
حدود القرار للانحدار متعدد الحدود والانحدار اللوجستي من النوع واحد مقابل البقية