ملاحظة
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
إيقاف التدريب المبكر في Gradient Boosting#
Gradient Boosting هي تقنية تجميعية تجمع بين عدة متعلمين ضعفاء، عادةً ما تكون أشجار القرار، لإنشاء نموذج تنبؤي قوي ومتين. تقوم بذلك بطريقة تكرارية، حيث تقوم كل مرحلة جديدة (شجرة) بتصحيح أخطاء المراحل السابقة.
إيقاف التدريب المبكر هو تقنية في Gradient Boosting تسمح لنا بإيجاد العدد الأمثل من التكرارات المطلوبة لبناء نموذج يعمم جيدًا على البيانات غير المرئية ويتجنب الإفراط في الملاءمة. والمفهوم بسيط: نخصص جزءًا من مجموعة بياناتنا كمجموعة تحقق (محددة باستخدام validation_fraction) لتقييم أداء النموذج أثناء التدريب.
مع بناء النموذج بشكل تكراري مع مراحل إضافية (أشجار)، يتم مراقبة أدائه على مجموعة التحقق كدالة لعدد الخطوات.
يصبح إيقاف التدريب المبكر فعالًا عندما يستقر أداء النموذج على مجموعة التحقق أو يسوء (ضمن الانحرافات المحددة بواسطة tol) على مدى عدد معين من المراحل المتتالية (محددة بواسطة n_iter_no_change). وهذا يشير إلى أن النموذج وصل إلى نقطة حيث قد تؤدي التكرارات الإضافية إلى الإفراط في الملاءمة، وقد حان الوقت لإيقاف التدريب.
يمكن الوصول إلى عدد المقدرين (الأشجار) في النموذج النهائي، عند تطبيق إيقاف التدريب المبكر، باستخدام خاصية n_estimators_. بشكل عام، يعتبر إيقاف التدريب المبكر أداة قيمة لتحقيق التوازن بين أداء النموذج والكفاءة في Gradient Boosting.
الرخصة: BSD 3 clause
# المؤلفون: مطوري scikit-learn
# معرف الرخصة: BSD-3-Clause
إعداد البيانات#
أولاً، نقوم بتحميل وإعداد مجموعة بيانات أسعار المنازل في كاليفورنيا للتدريب والتقييم. نقوم بتقسيم المجموعة إلى مجموعات فرعية، ثم نقسمها إلى مجموعات تدريب ومجموعات تحقق.
import time
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_california_housing
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
data = fetch_california_housing()
X, y = data.data[:600], data.target[:600]
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
تدريب النموذج ومقارنته#
يتم تدريب نموذجين من النوع GradientBoostingRegressor:
أحدهما مع إيقاف التدريب المبكر والآخر بدونه. الهدف هو مقارنة أدائهما. كما يتم حساب وقت التدريب و`n_estimators_`
المستخدمة في كلا النموذجين.
params = dict(n_estimators=1000, max_depth=5, learning_rate=0.1, random_state=42)
gbm_full = GradientBoostingRegressor(**params)
gbm_early_stopping = GradientBoostingRegressor(
**params,
validation_fraction=0.1,
n_iter_no_change=10,
)
start_time = time.time()
gbm_full.fit(X_train, y_train)
training_time_full = time.time() - start_time
n_estimators_full = gbm_full.n_estimators_
start_time = time.time()
gbm_early_stopping.fit(X_train, y_train)
training_time_early_stopping = time.time() - start_time
estimators_early_stopping = gbm_early_stopping.n_estimators_
حساب الخطأ#
يحسب الكود mean_squared_error لكل من
مجموعة التدريب ومجموعة التحقق للنموذجين المدربين في القسم السابق. يقوم بحساب الأخطاء لكل تكرار في عملية التعزيز. والهدف هو
تقييم أداء النموذجين ومدى تقاربهما.
train_errors_without = []
val_errors_without = []
train_errors_with = []
val_errors_with = []
for i, (train_pred, val_pred) in enumerate(
zip(
gbm_full.staged_predict(X_train),
gbm_full.staged_predict(X_val),
)
):
train_errors_without.append(mean_squared_error(y_train, train_pred))
val_errors_without.append(mean_squared_error(y_val, val_pred))
for i, (train_pred, val_pred) in enumerate(
zip(
gbm_early_stopping.staged_predict(X_train),
gbm_early_stopping.staged_predict(X_val),
)
):
train_errors_with.append(mean_squared_error(y_train, train_pred))
val_errors_with.append(mean_squared_error(y_val, val_pred))
عرض المقارنة#
يتضمن ثلاثة مخططات فرعية:
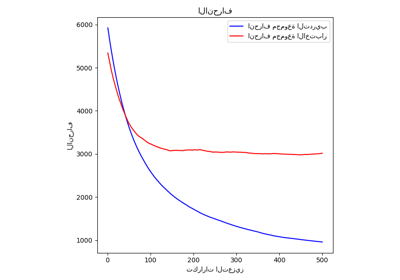
رسم أخطاء التدريب لكلا النموذجين على تكرارات التعزيز.
رسم أخطاء التحقق لكلا النموذجين على تكرارات التعزيز.
إنشاء مخطط شريطي لمقارنة أوقات التدريب والمقدر المستخدم في النموذجين مع وبدون إيقاف التدريب المبكر.
fig, axes = plt.subplots(ncols=3, figsize=(12, 4))
axes[0].plot(train_errors_without, label="gbm_full")
axes[0].plot(train_errors_with, label="gbm_early_stopping")
axes[0].set_xlabel("Boosting Iterations")
axes[0].set_ylabel("MSE (Training)")
axes[0].set_yscale("log")
axes[0].legend()
axes[0].set_title("Training Error")
axes[1].plot(val_errors_without, label="gbm_full")
axes[1].plot(val_errors_with, label="gbm_early_stopping")
axes[1].set_xlabel("Boosting Iterations")
axes[1].set_ylabel("MSE (Validation)")
axes[1].set_yscale("log")
axes[1].legend()
axes[1].set_title("Validation Error")
training_times = [training_time_full, training_time_early_stopping]
labels = ["gbm_full", "gbm_early_stopping"]
bars = axes[2].bar(labels, training_times)
axes[2].set_ylabel("Training Time (s)")
for bar, n_estimators in zip(bars, [n_estimators_full, estimators_early_stopping]):
height = bar.get_height()
axes[2].text(
bar.get_x() + bar.get_width() / 2,
height + 0.001,
f"Estimators: {n_estimators}",
ha="center",
va="bottom",
)
plt.tight_layout()
plt.show()
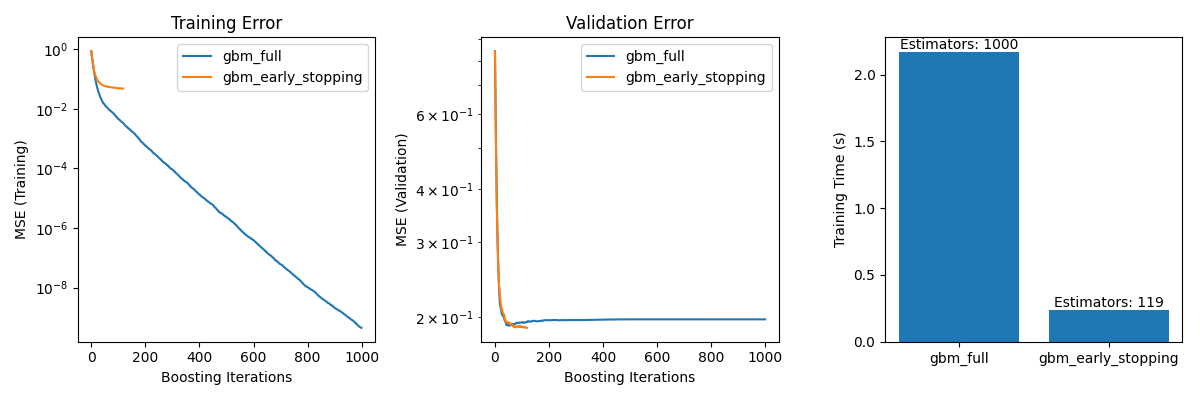
الفرق في خطأ التدريب بين gbm_full و
gbm_early_stopping ينبع من حقيقة أن gbm_early_stopping يخصص
validation_fraction من بيانات التدريب كمجموعة تحقق داخلية.
يتم اتخاذ قرار إيقاف التدريب المبكر بناءً على نتيجة التحقق الداخلية هذه.
ملخص#
في مثالنا باستخدام النموذج GradientBoostingRegressor
على مجموعة بيانات أسعار المنازل في كاليفورنيا، قمنا بتوضيح
الفوائد العملية لإيقاف التدريب المبكر:
منع الإفراط في الملاءمة: أظهرنا كيف يستقر خطأ التحقق أو يبدأ في الزيادة بعد نقطة معينة، مما يشير إلى أن النموذج يعمم بشكل أفضل على البيانات غير المرئية. يتم تحقيق ذلك عن طريق إيقاف عملية التدريب قبل حدوث الإفراط في الملاءمة.
تحسين كفاءة التدريب: قمنا بمقارنة أوقات التدريب بين النماذج مع وبدون إيقاف التدريب المبكر. حقق النموذج مع إيقاف التدريب المبكر دقة مماثلة بينما تطلب عددًا أقل بكثير من المقدرين، مما أدى إلى تدريب أسرع.
Total running time of the script: (0 minutes 4.206 seconds)
Related examples