ملاحظة
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
عرض توضيحي لخوارزمية التجميع الطيفي الثنائي#
هذا المثال يوضح كيفية إنشاء مجموعة بيانات لوحة الشطرنج وتجميعها
باستخدام خوارزمية SpectralBiclustering. تم تصميم خوارزمية التجميع الطيفي الثنائي خصيصًا لتجميع البيانات عن طريق
النظر في كل من الصفوف (العينات) والأعمدة (الميزات) للمصفوفة في نفس الوقت. تهدف إلى تحديد الأنماط ليس فقط بين العينات ولكن أيضًا داخل
المجموعات الفرعية من العينات، مما يسمح بالكشف عن البنية الموضعية داخل
البيانات. وهذا يجعل التجميع الطيفي الثنائي مناسبًا بشكل خاص لمجموعات البيانات
حيث يكون ترتيب الميزات أو ترتيبها ثابتًا، كما هو الحال في الصور أو السلاسل الزمنية أو الجينومات.
يتم إنشاء البيانات، ثم يتم خلطها وتمريرها إلى خوارزمية التجميع الطيفي الثنائي. يتم بعد ذلك إعادة ترتيب الصفوف والأعمدة للمصفوفة المخلوطة لرسم مجموعات التجميع الفرعية التي تم العثور عليها.
# المؤلفون: مطوري سكايلرن
# معرف الترخيص: BSD-3-Clause
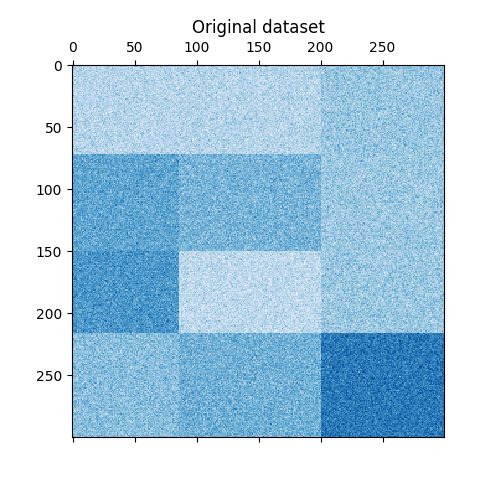
إنشاء بيانات العينة#
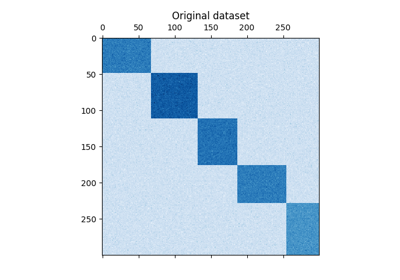
نقوم بإنشاء بيانات العينة باستخدام
make_checkerboard. يمثل كل بكسل داخل
shape=(300, 300) بلون قيمة من توزيع موحد. تتم إضافة الضجيج من التوزيع الطبيعي، حيث يتم اختيار القيمة
لـ noise هي الانحراف المعياري.
كما ترى، يتم توزيع البيانات على 12 خلية تجميع وهي مميزة جيدًا نسبيًا.
from sklearn.metrics import consensus_score
from sklearn.cluster import SpectralBiclustering
import numpy as np
from matplotlib import pyplot as plt
from sklearn.datasets import make_checkerboard
n_clusters = (4, 3)
data, rows, columns = make_checkerboard(
shape=(300, 300), n_clusters=n_clusters, noise=10, shuffle=False, random_state=42
)
plt.matshow(data, cmap=plt.cm.Blues)
plt.title("Original dataset")
_ = plt.show()
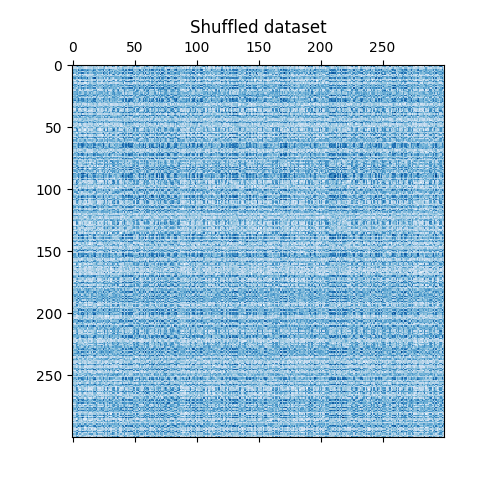
نقوم بخلط البيانات والهدف هو إعادة بنائها لاحقًا باستخدام
SpectralBiclustering.
# إنشاء قوائم من فهارس الصفوف والأعمدة المخلوطة
rng = np.random.RandomState(0)
row_idx_shuffled = rng.permutation(data.shape[0])
col_idx_shuffled = rng.permutation(data.shape[1])
نعيد تعريف البيانات المخلوطة ونرسمها. نلاحظ أننا فقدنا بنية مصفوفة البيانات الأصلية.
data = data[row_idx_shuffled][:, col_idx_shuffled]
plt.matshow(data, cmap=plt.cm.Blues)
plt.title("Shuffled dataset")
_ = plt.show()
تناسب SpectralBiclustering#
نقوم بتناسب النموذج ومقارنة التجميعات الناتجة مع الحقيقة الأرضية. لاحظ
أنه عند إنشاء النموذج، نقوم بتحديد نفس عدد التجميعات التي استخدمناها
لإنشاء مجموعة البيانات (n_clusters = (4, 3))، مما سيساهم في
الحصول على نتيجة جيدة.
model = SpectralBiclustering(
n_clusters=n_clusters, method="log", random_state=0)
model.fit(data)
# حساب التشابه بين مجموعتين من مجموعات التجميع الفرعية
score = consensus_score(
model.biclusters_, (rows[:, row_idx_shuffled],
columns[:, col_idx_shuffled])
)
print(f"consensus score: {score:.1f}")
consensus score: 1.0
النتيجة بين 0 و 1، حيث 1 يتوافق مع تطابق مثالي. إنه يظهر جودة التجميع الثنائي.
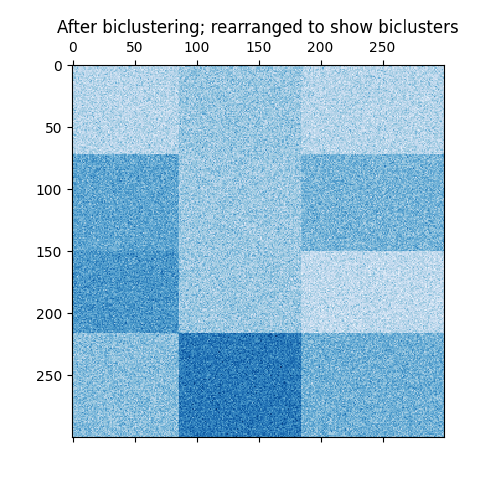
رسم النتائج#
الآن، نقوم بإعادة ترتيب البيانات بناءً على تسميات الصفوف والأعمدة التي قام النموذج بتعيينها
SpectralBiclustering بترتيب تصاعدي ورسمها مرة أخرى. تتراوح row_labels_ من 0 إلى 3، بينما تتراوح column_labels_
من 0 إلى 2، مما يمثل ما مجموعه 4 مجموعات تجميع لكل صف و 3 مجموعات
لكل عمود.
# إعادة ترتيب الصفوف أولاً ثم الأعمدة.
reordered_rows = data[np.argsort(model.row_labels_)]
reordered_data = reordered_rows[:, np.argsort(model.column_labels_)]
plt.matshow(reordered_data, cmap=plt.cm.Blues)
plt.title("After biclustering; rearranged to show biclusters")
_ = plt.show()
كخطوة أخيرة، نريد توضيح العلاقات بين تسميات الصفوف
والأعمدة التي قام النموذج بتعيينها. لذلك، نقوم بإنشاء شبكة باستخدام
numpy.outer، والتي تأخذ row_labels_ و column_labels_
المرتبة وتضيف 1 إلى كل منها لضمان أن تبدأ التسميات من 1 بدلاً من 0 لتحسين
العرض المرئي.
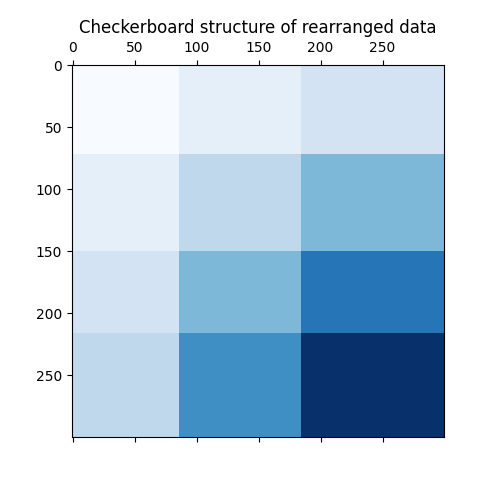
حاصل الضرب الخارجي لمتجهات تسميات الصفوف والأعمدة يظهر تمثيلًا لهيكل لوحة الشطرنج، حيث يتم تمثيل مجموعات مختلفة من تسميات الصفوف والأعمدة بظلال مختلفة من اللون الأزرق.
Total running time of the script: (0 minutes 0.716 seconds)
Related examples

التجميع الثنائي للمستندات باستخدام خوارزمية التجميع الطيفي المشترك

مقارنة طرق الربط الهرمي المختلفة على مجموعات بيانات تجريبية