ملاحظة
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
دمج المتنبئات باستخدام التكديس#
يشير التكديس إلى طريقة لمزج المقدرات. في هذه الاستراتيجية، يتم ملاءمة بعض المقدرات بشكل فردي على بعض بيانات التدريب بينما يتم تدريب مقدر نهائي باستخدام التنبؤات المكدسة لهذه المقدرات الأساسية.
في هذا المثال، نوضح حالة الاستخدام التي يتم فيها تكديس مُنحدرات مختلفة معًا ويتم استخدام مُنحدِر خطي مُعاقَب نهائي لإخراج التنبؤ. نقارن أداء كل مُنحدِر فردي مع استراتيجية التكديس. يحسن التكديس الأداء العام بشكل طفيف.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
تنزيل مجموعة البيانات#
سنستخدم مجموعة بيانات Ames Housing التي تم تجميعها لأول مرة بواسطة Dean De Cock وأصبحت أكثر شهرة بعد استخدامها في تحدي Kaggle. إنها مجموعة من 1460 منزلًا سكنيًا في Ames، Iowa، كل منها موصوف بـ 80 ميزة. سنستخدمها للتنبؤ بالسعر اللوغاريتمي النهائي للمنازل. في هذا المثال، سنستخدم 20 ميزة فقط من أكثر الميزات إثارة للاهتمام تم اختيارها باستخدام GradientBoostingRegressor () ونحد من عدد الإدخالات (لن نتطرق هنا إلى التفاصيل حول كيفية تحديد الميزات الأكثر إثارة للاهتمام).
لا يتم شحن مجموعة بيانات Ames Housing مع scikit-learn، وبالتالي سنقوم بجلبها من OpenML.
import numpy as np
from sklearn.datasets import fetch_openml
from sklearn.utils import shuffle
def load_ames_housing():
df = fetch_openml(name="house_prices", as_frame=True)
X = df.data
y = df.target
features = [
"YrSold",
"HeatingQC",
"Street",
"YearRemodAdd",
"Heating",
"MasVnrType",
"BsmtUnfSF",
"Foundation",
"MasVnrArea",
"MSSubClass",
"ExterQual",
"Condition2",
"GarageCars",
"GarageType",
"OverallQual",
"TotalBsmtSF",
"BsmtFinSF1",
"HouseStyle",
"MiscFeature",
"MoSold",
]
X = X.loc[:, features]
X, y = shuffle(X, y, random_state=0)
X = X.iloc[:600]
y = y.iloc[:600]
return X, np.log(y)
X, y = load_ames_housing()
إنشاء خط أنابيب لمعالجة البيانات مسبقًا#
قبل أن نتمكن من استخدام مجموعة بيانات Ames، ما زلنا بحاجة إلى إجراء بعض المعالجة المسبقة. أولاً، سنحدد الأعمدة الفئوية والرقمية لمجموعة البيانات لإنشاء الخطوة الأولى من خط الأنابيب.
from sklearn.compose import make_column_selector
cat_selector = make_column_selector(dtype_include=object)
num_selector = make_column_selector(dtype_include=np.number)
cat_selector(X)
['HeatingQC', 'Street', 'Heating', 'MasVnrType', 'Foundation', 'ExterQual', 'Condition2', 'GarageType', 'HouseStyle', 'MiscFeature']
num_selector(X)
['YrSold', 'YearRemodAdd', 'BsmtUnfSF', 'MasVnrArea', 'MSSubClass', 'GarageCars', 'OverallQual', 'TotalBsmtSF', 'BsmtFinSF1', 'MoSold']
بعد ذلك، سنحتاج إلى تصميم خطوط أنابيب المعالجة المسبقة التي تعتمد على المُنحدِر النهائي. إذا كان المُنحدِر النهائي نموذجًا خطيًا، فيجب على المرء ترميز الفئات بترميز واحد ساخن. إذا كان المُنحدِر النهائي نموذجًا قائمًا على الشجرة، فسيكون المُرمز الترتيبي كافيًا. إلى جانب ذلك، يجب توحيد القيم الرقمية للنموذج الخطي بينما يمكن معالجة البيانات الرقمية الأولية كما هي بواسطة نموذج قائم على الشجرة. ومع ذلك، يحتاج كلا النموذجين إلى أداة إكمال للتعامل مع القيم المفقودة.
سنقوم أولاً بتصميم خط الأنابيب المطلوب للنماذج القائمة على الشجرة.
from sklearn.compose import make_column_transformer
from sklearn.impute import SimpleImputer
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import OrdinalEncoder
cat_tree_processor = OrdinalEncoder(
handle_unknown="use_encoded_value",
unknown_value=-1,
encoded_missing_value=-2,
)
num_tree_processor = SimpleImputer(strategy="mean", add_indicator=True)
tree_preprocessor = make_column_transformer(
(num_tree_processor, num_selector), (cat_tree_processor, cat_selector)
)
tree_preprocessor
بعد ذلك، سنحدد الآن المعالج المسبق المستخدم عندما يكون المُنحدِر النهائي نموذجًا خطيًا.
from sklearn.preprocessing import OneHotEncoder, StandardScaler
cat_linear_processor = OneHotEncoder(handle_unknown="ignore")
num_linear_processor = make_pipeline(
StandardScaler(), SimpleImputer(strategy="mean", add_indicator=True)
)
linear_preprocessor = make_column_transformer(
(num_linear_processor, num_selector), (cat_linear_processor, cat_selector)
)
linear_preprocessor
مكدس المتنبئات على مجموعة بيانات واحدة#
يكون من الممل في بعض الأحيان العثور على النموذج الذي سيكون أفضل أداءً على مجموعة بيانات معينة. يوفر التكديس بديلاً عن طريق دمج مخرجات العديد من المتعلمين، دون الحاجة إلى اختيار نموذج محدد. عادة ما يكون أداء التكديس قريبًا من أفضل نموذج، وأحيانًا يمكن أن يتفوق على أداء التنبؤ لكل نموذج فردي.
هنا، نقوم بدمج 3 متعلمين (خطي وغير خطي) ونستخدم مُنحدِر ريدج لدمج مخرجاتهم معًا.
ملاحظة
على الرغم من أننا سننشئ خطوط أنابيب جديدة مع المعالجات التي كتبناها في
القسم السابق للمتعلمين الثلاثة، فإن المقدر النهائي
RidgeCV() لا يحتاج إلى معالجة مسبقة
للبيانات لأنه سيتم تغذيته بالمخرجات المعالجة مسبقًا من المتعلمين
الثلاثة.
from sklearn.linear_model import LassoCV
lasso_pipeline = make_pipeline(linear_preprocessor, LassoCV())
lasso_pipeline
from sklearn.ensemble import RandomForestRegressor
rf_pipeline = make_pipeline(tree_preprocessor, RandomForestRegressor(random_state=42))
rf_pipeline
from sklearn.ensemble import HistGradientBoostingRegressor
gbdt_pipeline = make_pipeline(
tree_preprocessor, HistGradientBoostingRegressor(random_state=0)
)
gbdt_pipeline
from sklearn.ensemble import StackingRegressor
from sklearn.linear_model import RidgeCV
estimators = [
("الغابة العشوائية", rf_pipeline),
("Lasso", lasso_pipeline),
("التعزيز المتدرج", gbdt_pipeline),
]
stacking_regressor = StackingRegressor(estimators=estimators, final_estimator=RidgeCV())
stacking_regressor
قياس ورسم النتائج#
الآن يمكننا استخدام مجموعة بيانات Ames Housing لإجراء التنبؤات. نتحقق من أداء كل متنبئ فردي بالإضافة إلى مكدس المُنحدرات.
import time
import matplotlib.pyplot as plt
from sklearn.metrics import PredictionErrorDisplay
from sklearn.model_selection import cross_val_predict, cross_validate
fig, axs = plt.subplots(2, 2, figsize=(9, 7))
axs = np.ravel(axs)
for ax, (name, est) in zip(
axs, estimators + [("مُنحدِر التكديس", stacking_regressor)]
):
scorers = {"R2": "r2", "MAE": "neg_mean_absolute_error"}
start_time = time.time()
scores = cross_validate(
est, X, y, scoring=list(scorers.values()), n_jobs=-1, verbose=0
)
elapsed_time = time.time() - start_time
y_pred = cross_val_predict(est, X, y, n_jobs=-1, verbose=0)
scores = {
key: (
f"{np.abs(np.mean(scores[f'test_{value}'])):.2f} +- "
f"{np.std(scores[f'test_{value}']):.2f}"
)
for key, value in scorers.items()
}
display = PredictionErrorDisplay.from_predictions(
y_true=y,
y_pred=y_pred,
kind="actual_vs_predicted",
ax=ax,
scatter_kwargs={"alpha": 0.2, "color": "tab:blue"},
line_kwargs={"color": "tab:red"},
)
ax.set_title(f"{name}\nالتقييم في {elapsed_time:.2f} ثانية")
for name, score in scores.items():
ax.plot([], [], " ", label=f"{name}: {score}")
ax.legend(loc="upper left")
plt.suptitle("المتنبئات الفردية مقابل المتنبئات المكدسة")
plt.tight_layout()
plt.subplots_adjust(top=0.9)
plt.show()
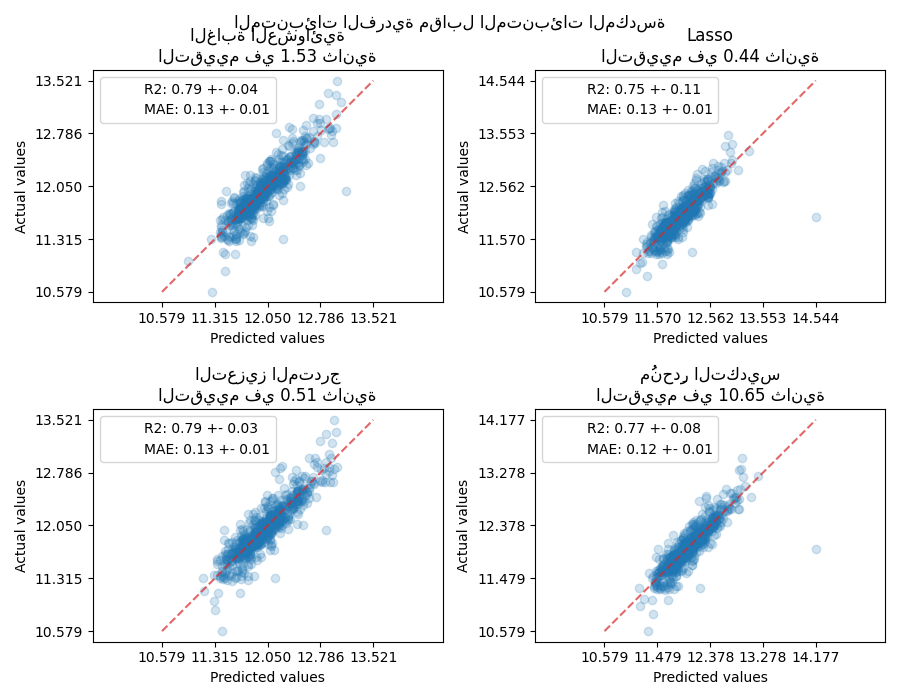
سيجمع مُنحدِر التكديس نقاط القوة لمختلف المُنحدرات. ومع ذلك، نرى أيضًا أن تدريب مُنحدِر التكديس مكلف حسابيًا أكثر.
Total running time of the script: (0 minutes 26.930 seconds)
Related examples
مقارنة الغابات العشوائية ومقدر المخرجات المتعددة التلوي