ملاحظة
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
مقارنة ترميز الهدف مع الترميزات الأخرى#
يستخدم TargetEncoder قيمة الهدف لترميز كل ميزة
فئة. في هذا المثال، سنقارن بين ثلاثة أساليب مختلفة
لمعالجة الميزات الفئوية: TargetEncoder،
OrdinalEncoder، OneHotEncoder وإسقاط الفئة.
ملاحظة
fit(X, y).transform(X) لا يساوي fit_transform(X, y) لأن
مخطط التثبيت المتقاطع مستخدم في fit_transform للترميز. راجع
دليل المستخدم. للحصول على التفاصيل.
# المؤلفون: مطوري scikit-learn
# معرف SPDX-License: BSD-3-Clause
تحميل البيانات من OpenML#
أولاً، نقوم بتحميل مجموعة بيانات مراجعات النبيذ، حيث الهدف هو النقاط المعطاة من قبل المراجع:
from sklearn.datasets import fetch_openml
wine_reviews = fetch_openml(data_id=42074, as_frame=True)
df = wine_reviews.frame
df.head()
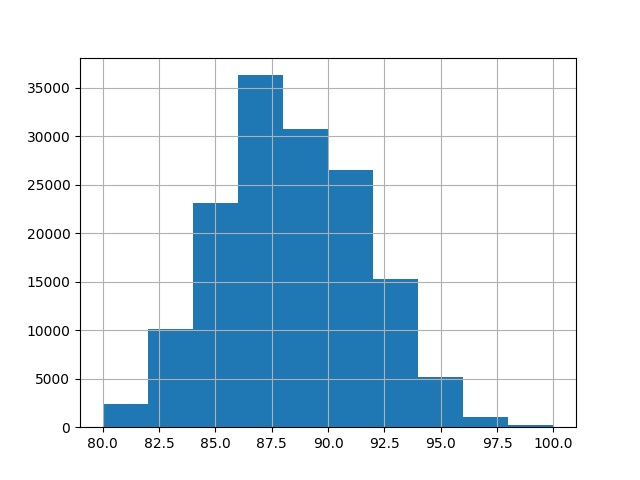
لهذا المثال، نستخدم المجموعة الفرعية التالية من الميزات العددية والفئوية الميزات في البيانات. الهدف هي قيم مستمرة من 80 إلى 100:
numerical_features = ["price"]
categorical_features = [
"country",
"province",
"region_1",
"region_2",
"variety",
"winery",
]
target_name = "points"
X = df[numerical_features + categorical_features]
y = df[target_name]
_ = y.hist()
تدريب وتقييم خطوط الأنابيب مع ترميزات مختلفة#
في هذا القسم، سنقيم خطوط الأنابيب مع
HistGradientBoostingRegressor مع استراتيجيات ترميز مختلفة.
أولاً، سنقوم بكتابة قائمة بالترميزات التي سنستخدمها لمعالجة مسبقة
الميزات الفئوية:
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import OneHotEncoder, OrdinalEncoder, TargetEncoder
categorical_preprocessors = [
("drop", "drop"),
("ordinal", OrdinalEncoder(handle_unknown="use_encoded_value", unknown_value=-1)),
(
"one_hot",
OneHotEncoder(handle_unknown="ignore", max_categories=20, sparse_output=False),
),
("target", TargetEncoder(target_type="continuous")),
]
بعد ذلك، نقيم النماذج باستخدام التحقق المتقاطع ونقوم بتسجيل النتائج:
from sklearn.ensemble import HistGradientBoostingRegressor
from sklearn.model_selection import cross_validate
from sklearn.pipeline import make_pipeline
n_cv_folds = 3
max_iter = 20
results = []
def evaluate_model_and_store(name, pipe):
result = cross_validate(
pipe,
X,
y,
scoring="neg_root_mean_squared_error",
cv=n_cv_folds,
return_train_score=True,
)
rmse_test_score = -result["test_score"]
rmse_train_score = -result["train_score"]
results.append(
{
"preprocessor": name,
"rmse_test_mean": rmse_test_score.mean(),
"rmse_test_std": rmse_train_score.std(),
"rmse_train_mean": rmse_train_score.mean(),
"rmse_train_std": rmse_train_score.std(),
}
)
for name, categorical_preprocessor in categorical_preprocessors:
preprocessor = ColumnTransformer(
[
("numerical", "passthrough", numerical_features),
("categorical", categorical_preprocessor, categorical_features),
]
)
pipe = make_pipeline(
preprocessor, HistGradientBoostingRegressor(random_state=0, max_iter=max_iter)
)
evaluate_model_and_store(name, pipe)
دعم الميزات الفئوية الأصلي#
في هذا القسم، نقوم ببناء وتقييم خط أنابيب يستخدم الدعم الفئوي الأصلي
في HistGradientBoostingRegressor،
الذي يدعم ما يصل إلى 255 فئة فريدة فقط. في مجموعة بياناتنا، معظم
الميزات الفئوية لديها أكثر من 255 فئة فريدة:
n_unique_categories = df[categorical_features].nunique().sort_values(ascending=False)
n_unique_categories
winery 14810
region_1 1236
variety 632
province 455
country 48
region_2 18
dtype: int64
للتحايل على القيد أعلاه، نقوم بتقسيم الميزات الفئوية إلى ميزات ذات عدد قليل من الفئات وميزات ذات عدد كبير من الفئات. سيتم ترميز الميزات ذات العدد الكبير من الفئات وسيتم استخدام الميزات ذات العدد القليل من الفئات في التدرج الدعم الفئوي الأصلي.
high_cardinality_features = n_unique_categories[n_unique_categories > 255].index
low_cardinality_features = n_unique_categories[n_unique_categories <= 255].index
mixed_encoded_preprocessor = ColumnTransformer(
[
("numerical", "passthrough", numerical_features),
(
"high_cardinality",
TargetEncoder(target_type="continuous"),
high_cardinality_features,
),
(
"low_cardinality",
OrdinalEncoder(handle_unknown="use_encoded_value", unknown_value=-1),
low_cardinality_features,
),
],
verbose_feature_names_out=False,
)
# يجب تعيين إخراج المعالج المسبق إلى pandas بحيث يمكن
# نموذج التدرج الكشف عن الميزات ذات العدد القليل من الفئات.
mixed_encoded_preprocessor.set_output(transform="pandas")
mixed_pipe = make_pipeline(
mixed_encoded_preprocessor,
HistGradientBoostingRegressor(
random_state=0, max_iter=max_iter, categorical_features=low_cardinality_features
),
)
mixed_pipe
أخيرًا، نقوم بتقييم خط الأنابيب باستخدام التحقق المتقاطع وتسجيل النتائج:
evaluate_model_and_store("mixed_target", mixed_pipe)
رسم النتائج#
في هذا القسم، نقوم بعرض النتائج عن طريق رسم درجات الاختبار والتدريب:
import matplotlib.pyplot as plt
import pandas as pd
results_df = (
pd.DataFrame(results).set_index("preprocessor").sort_values("rmse_test_mean")
)
fig, (ax1, ax2) = plt.subplots(
1, 2, figsize=(12, 8), sharey=True, constrained_layout=True
)
xticks = range(len(results_df))
name_to_color = dict(
zip((r["preprocessor"] for r in results), ["C0", "C1", "C2", "C3", "C4"])
)
for subset, ax in zip(["test", "train"], [ax1, ax2]):
mean, std = f"rmse_{subset}_mean", f"rmse_{subset}_std"
data = results_df[[mean, std]].sort_values(mean)
ax.bar(
x=xticks,
height=data[mean],
yerr=data[std],
width=0.9,
color=[name_to_color[name] for name in data.index],
)
ax.set(
title=f"RMSE ({subset.title()})",
xlabel="Encoding Scheme",
xticks=xticks,
xticklabels=data.index,
)
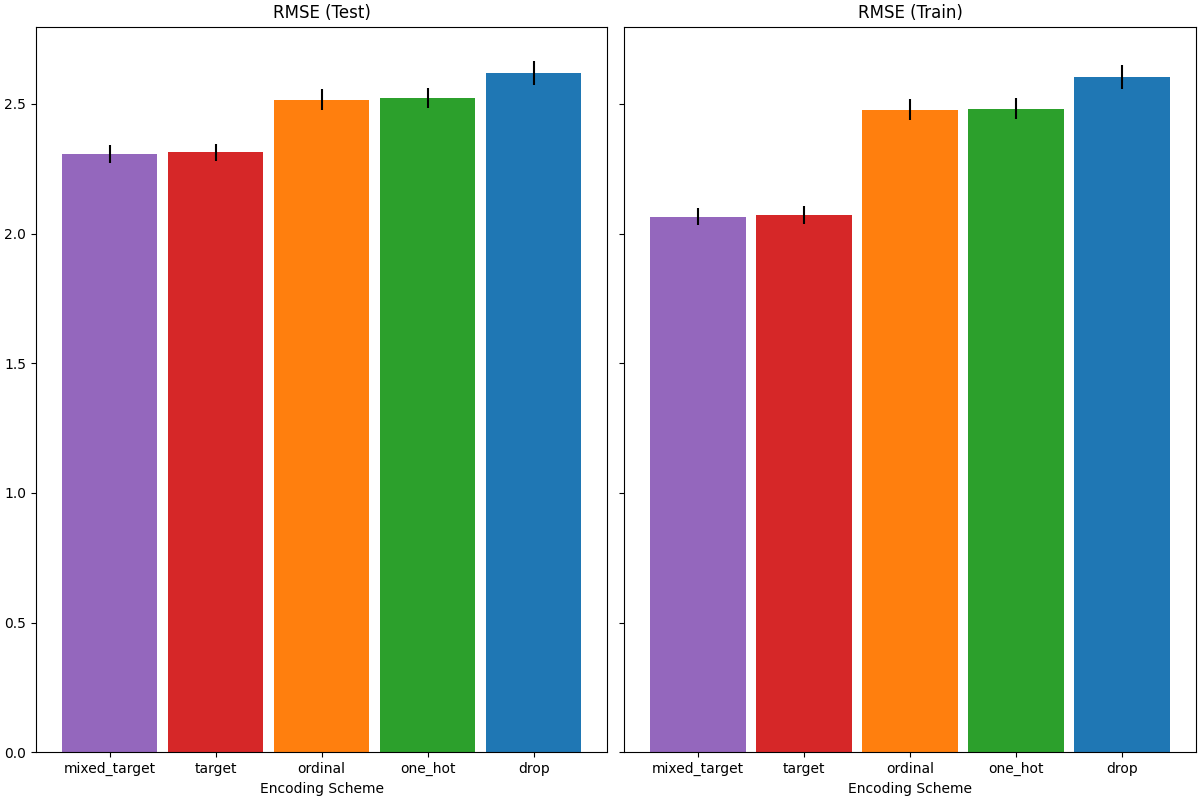
عند تقييم الأداء التنبؤي على مجموعة الاختبار، يؤدي إسقاط الفئات تؤدي إلى أسوأ أداء، ويؤدي ترميز الهدف إلى أفضل أداء. يمكن تفسير هذا على النحو التالي:
يؤدي إسقاط الميزات الفئوية إلى جعل خط الأنابيب أقل تعبيرًا وتحت التلائم
نتيجة لذلك؛
- نظرًا لارتفاع عدد الفئات ولتقليل وقت التدريب، يستخدم مخطط الترميز أحادي الساخن
max_categories=20 الذي يمنع الميزات من التوسع كثيرًا، والذي يمكن أن يؤدي إلى نقص التلائم.
- إذا لم نقم بتعيين max_categories=20، فمن المحتمل أن يؤدي مخطط الترميز أحادي الساخن إلى
جعل خط الأنابيب مفرط التلائم حيث ينفجر عدد الميزات مع حدوث فئات نادرة
التي ترتبط بالهدف عن طريق الصدفة (على مجموعة التدريب فقط)؛
- يفرض الترميز الترتيبي ترتيبًا تعسفيًا على الميزات التي يتم معاملتها بعد ذلك
كقيم عددية بواسطة
HistGradientBoostingRegressor. نظرًا لأن هذا
النموذج يجمع الميزات العددية في 256 صنفًا لكل ميزة، يمكن تجميع العديد من الفئات غير ذات الصلة معًا ونتيجة لذلك يمكن أن يؤدي خط الأنابيب العام إلى نقص التلائم؛
- عند استخدام ترميز الهدف، يحدث نفس التجميع، ولكن نظرًا لأن القيم المشفرة
يتم ترتيبها إحصائيًا بالارتباط الهامشي مع متغير الهدف،
التجميع الذي يستخدمه HistGradientBoostingRegressor
منطقي ويؤدي إلى نتائج جيدة: يعمل مزيج الترميز المستهدف المملس والتجميع
كاستراتيجية تنظيم جيدة ضد
الإفراط في التلائم مع عدم الحد من تعبيرية خط الأنابيب كثيرًا.
Total running time of the script: (0 minutes 25.366 seconds)
Related examples