ملاحظة
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
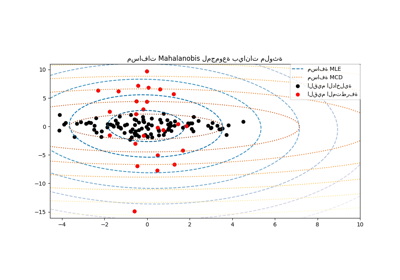
تقدير التغاير القوي مقابل التجريبي#
تقدير أقصى احتمال للتغاير المعتاد حساس جدًا لوجود القيم المتطرفة في مجموعة البيانات. في مثل هذه الحالة، سيكون من الأفضل استخدام مقدر قوي للتغاير لضمان أن يكون التقدير مقاوماً للملاحظات "الخاطئة" في مجموعة البيانات. [1], [2]
مقدر الحد الأدنى لمحدد التغاير#
مقدر الحد الأدنى لمحدد التغاير هو مقدر قوي، عالي نقطة الانهيار (أي يمكن استخدامه لتقدير مصفوفة التغاير لمجموعات البيانات شديدة التلوث، حتى :math:` rac{n_ ext{samples} - n_ ext{features}-1}{2}` قيم متطرفة) للتغاير. الفكرة هي إيجاد :math:` rac{n_ ext{samples} + n_ ext{features}+1}{2}` ملاحظات يكون التغاير التجريبي لها هو المحدد الأصغر، مما ينتج عنه مجموعة فرعية "نقية" من الملاحظات التي يمكن من خلالها حساب التقديرات القياسية للموقع والتغاير. بعد خطوة تصحيح تهدف إلى تعويض حقيقة أن التقديرات تم تعلمها من جزء فقط من البيانات الأولية، ننتهي بتقديرات قوية لموقع مجموعة البيانات وتغايرها.
تم تقديم مقدر الحد الأدنى لمحدد التغاير (MCD) بواسطة P.J.Rousseuw في [3].
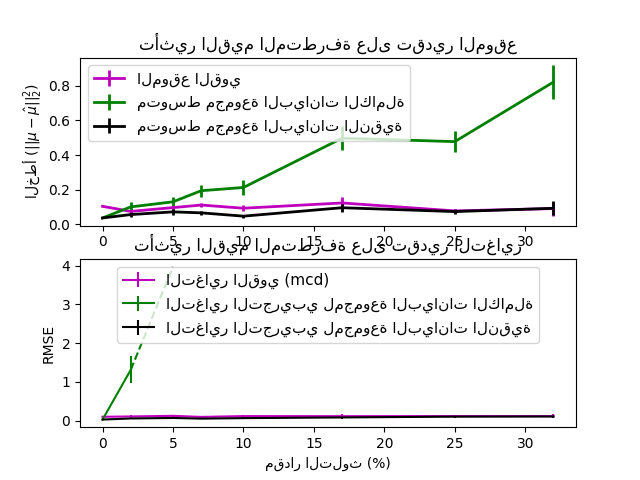
التقييم#
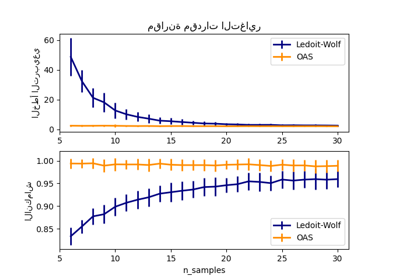
في هذا المثال، نقارن أخطاء التقدير التي تحدث عند استخدام أنواع مختلفة من تقديرات الموقع والتغاير على مجموعات بيانات ملوثة موزعة غاوسية:
المتوسط والتغاير التجريبي لمجموعة البيانات الكاملة، والتي تنهار بمجرد وجود قيم متطرفة في مجموعة البيانات
MCD القوي، الذي يحتوي على خطأ منخفض شريطة \(n_ ext{samples} > 5n_ ext{features}\)
المتوسط والتغاير التجريبي للملاحظات المعروف أنها جيدة. يمكن اعتبار هذا بمثابة تقدير MCD "مثالي"، لذلك يمكن للمرء الوثوق بتنفيذنا من خلال المقارنة مع هذه الحالة.
المراجع#
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
import matplotlib.font_manager
import matplotlib.pyplot as plt
import numpy as np
from sklearn.covariance import EmpiricalCovariance, MinCovDet
# إعدادات المثال
n_samples = 80
n_features = 5
repeat = 10
range_n_outliers = np.concatenate(
(
np.linspace(0, n_samples / 8, 5),
np.linspace(n_samples / 8, n_samples / 2, 5)[1:-1],
)
).astype(int)
# تعريف المصفوفات لتخزين النتائج
err_loc_mcd = np.zeros((range_n_outliers.size, repeat))
err_cov_mcd = np.zeros((range_n_outliers.size, repeat))
err_loc_emp_full = np.zeros((range_n_outliers.size, repeat))
err_cov_emp_full = np.zeros((range_n_outliers.size, repeat))
err_loc_emp_pure = np.zeros((range_n_outliers.size, repeat))
err_cov_emp_pure = np.zeros((range_n_outliers.size, repeat))
# العملية الحسابية
for i, n_outliers in enumerate(range_n_outliers):
for j in range(repeat):
rng = np.random.RandomState(i * j)
# إنشاء البيانات
X = rng.randn(n_samples, n_features)
# إضافة بعض القيم المتطرفة
outliers_index = rng.permutation(n_samples)[:n_outliers]
outliers_offset = 10.0 * (
np.random.randint(2, size=(n_outliers, n_features)) - 0.5
)
X[outliers_index] += outliers_offset
inliers_mask = np.ones(n_samples).astype(bool)
inliers_mask[outliers_index] = False
# ملاءمة مقدر قوي للحد الأدنى لمحدد التغاير (MCD) مع البيانات
mcd = MinCovDet().fit(X)
# قارن التقديرات الأولية القوية مع الموقع والتغاير الحقيقيين
err_loc_mcd[i, j] = np.sum(mcd.location_**2)
err_cov_mcd[i, j] = mcd.error_norm(np.eye(n_features))
# قارن المقدرات المستفادة من مجموعة البيانات الكاملة بالمعلمات
# الحقيقية
err_loc_emp_full[i, j] = np.sum(X.mean(0) ** 2)
err_cov_emp_full[i, j] = (
EmpiricalCovariance().fit(X).error_norm(np.eye(n_features))
)
# قارن مع تغاير تجريبي مستفاد من مجموعة بيانات نقية
# (أي mcd "مثالي")
pure_X = X[inliers_mask]
pure_location = pure_X.mean(0)
pure_emp_cov = EmpiricalCovariance().fit(pure_X)
err_loc_emp_pure[i, j] = np.sum(pure_location**2)
err_cov_emp_pure[i, j] = pure_emp_cov.error_norm(np.eye(n_features))
# عرض النتائج
font_prop = matplotlib.font_manager.FontProperties(size=11)
plt.subplot(2, 1, 1)
lw = 2
plt.errorbar(
range_n_outliers,
err_loc_mcd.mean(1),
yerr=err_loc_mcd.std(1) / np.sqrt(repeat),
label="الموقع القوي",
lw=lw,
color="m",
)
plt.errorbar(
range_n_outliers,
err_loc_emp_full.mean(1),
yerr=err_loc_emp_full.std(1) / np.sqrt(repeat),
label="متوسط مجموعة البيانات الكاملة",
lw=lw,
color="green",
)
plt.errorbar(
range_n_outliers,
err_loc_emp_pure.mean(1),
yerr=err_loc_emp_pure.std(1) / np.sqrt(repeat),
label="متوسط مجموعة البيانات النقية",
lw=lw,
color="black",
)
plt.title("تأثير القيم المتطرفة على تقدير الموقع")
plt.ylabel(r"الخطأ ($||\mu - \hat{\mu}||_2^2$)")
plt.legend(loc="upper left", prop=font_prop)
plt.subplot(2, 1, 2)
x_size = range_n_outliers.size
plt.errorbar(
range_n_outliers,
err_cov_mcd.mean(1),
yerr=err_cov_mcd.std(1),
label="التغاير القوي (mcd)",
color="m",
)
plt.errorbar(
range_n_outliers[: (x_size // 5 + 1)],
err_cov_emp_full.mean(1)[: (x_size // 5 + 1)],
yerr=err_cov_emp_full.std(1)[: (x_size // 5 + 1)],
label="التغاير التجريبي لمجموعة البيانات الكاملة",
color="green",
)
plt.plot(
range_n_outliers[(x_size // 5): (x_size // 2 - 1)],
err_cov_emp_full.mean(1)[(x_size // 5): (x_size // 2 - 1)],
color="green",
ls="--",
)
plt.errorbar(
range_n_outliers,
err_cov_emp_pure.mean(1),
yerr=err_cov_emp_pure.std(1),
label="التغاير التجريبي لمجموعة البيانات النقية",
color="black",
)
plt.title("تأثير القيم المتطرفة على تقدير التغاير")
plt.xlabel("مقدار التلوث (%)")
plt.ylabel("RMSE")
plt.legend(loc="upper center", prop=font_prop)
plt.show()
Total running time of the script: (0 minutes 2.801 seconds)
Related examples