ملاحظة
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
هذا مثال على تطبيق NMF و
LatentDirichletAllocation على مجموعة من الوثائق واستخراج نماذج إضافية لهيكل الموضوعات في المجموعة. المخرجات عبارة عن رسم بياني للموضوعات، يمثل كل منها رسمًا بيانيًا باستخدام عدد قليل من الكلمات العليا بناءً على الأوزان.
يتم تطبيق تحليل المصفوفات غير السالبة مع دالتين مختلفتين للهدف: معيار فروبينيوس، والتباعد العام لكولباك-لايبلر. الأخير يعادل الفهرسة الدلالية الكامنة الاحتمالية.
يجب أن تجعل المعلمات الافتراضية (n_samples / n_features / n_components) المثال قابلاً للتشغيل في بضع عشرات من الثواني. يمكنك محاولة زيادة أبعاد المشكلة، ولكن كن على دراية بأن التعقيد الزمني هو كثير الحدود في NMF. في LDA، التعقيد الزمني يتناسب مع (n_samples * iterations).

تحميل مجموعة البيانات...
تم في 1.889s.
استخراج ميزات tf-idf لـ NMF...
تم في 0.280s.
استخراج ميزات tf لـ LDA...
تم في 0.294s.
ملاءمة نموذج NMF (معيار فروبينيوس) مع ميزات tf-idf، n_samples=2000 و n_features=1000...
تم في 0.066s.
ملاءمة نموذج NMF (التباعد العام لكولباك-لايبلر) مع ميزات tf-idf، n_samples=2000 و n_features=1000...
تم في 1.260s.
ملاءمة نموذج MiniBatchNMF (معيار فروبينيوس) مع ميزات tf-idf n_samples=2000 و n_features=1000، batch_size=128...
تم في 0.156s.
ملاءمة نموذج MiniBatchNMF (التباعد العام لكولباك-لايبلر) مع ميزات tf-idf، n_samples=2000 و n_features=1000، batch_size=128...
تم في 0.411s.
ملاءمة نماذج LDA مع ميزات tf، n_samples=2000 و n_features=1000...
تم في 3.386s.
# المؤلفون: مطوري scikit-learn
# معرف SPDX-License: BSD-3-Clause
from time import time
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_20newsgroups
from sklearn.decomposition import NMF, LatentDirichletAllocation, MiniBatchNMF
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
n_samples = 2000
n_features = 1000
n_components = 10
n_top_words = 20
batch_size = 128
init = "nndsvda"
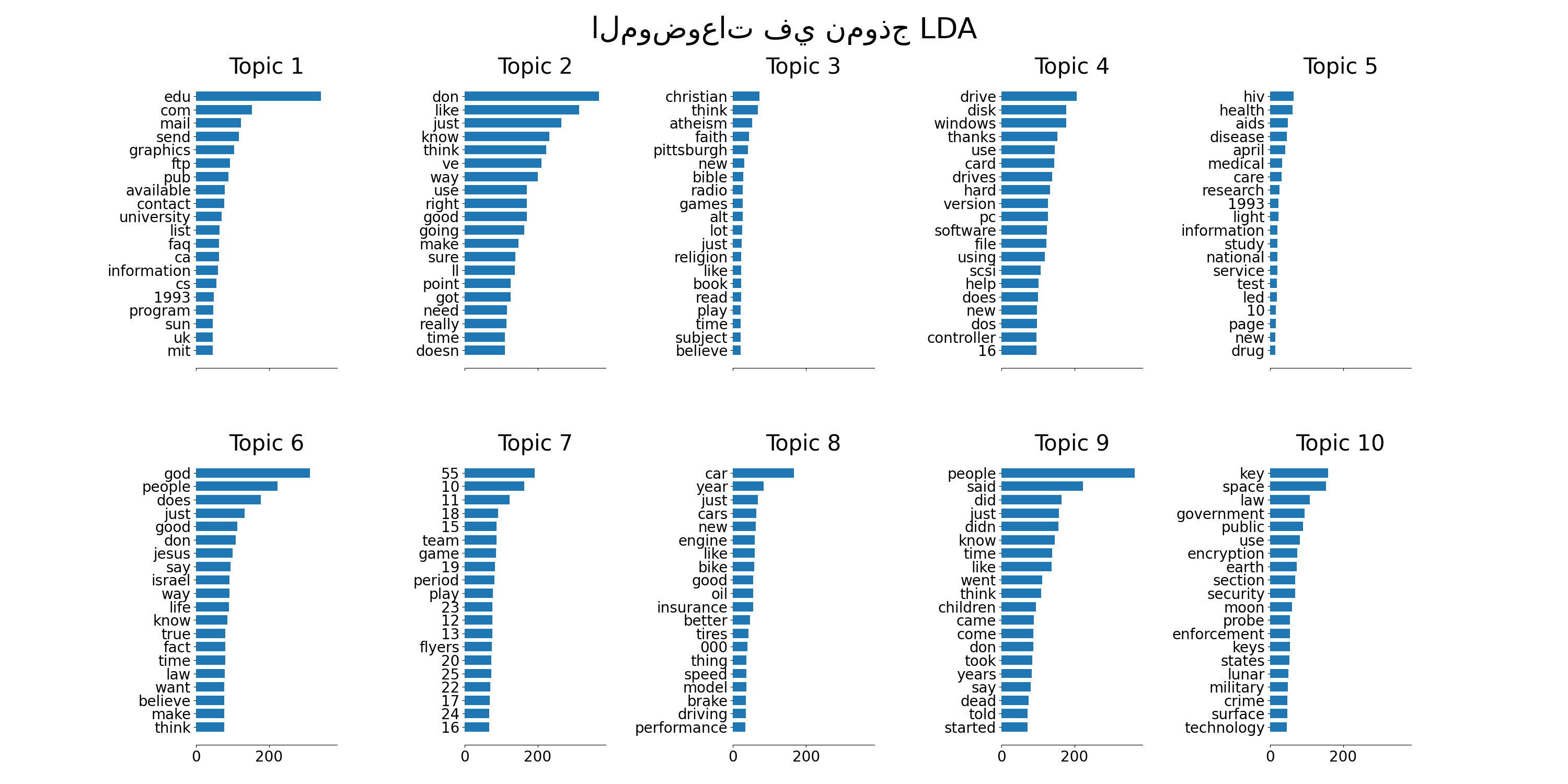
def plot_top_words(model, feature_names, n_top_words, title):
fig, axes = plt.subplots(2, 5, figsize=(30, 15), sharex=True)
axes = axes.flatten()
for topic_idx, topic in enumerate(model.components_):
top_features_ind = topic.argsort()[-n_top_words:]
top_features = feature_names[top_features_ind]
weights = topic[top_features_ind]
ax = axes[topic_idx]
ax.barh(top_features, weights, height=0.7)
ax.set_title(f"Topic {topic_idx +1}", fontdict={"fontsize": 30})
ax.tick_params(axis="both", which="major", labelsize=20)
for i in "top right left".split():
ax.spines[i].set_visible(False)
fig.suptitle(title, fontsize=40)
plt.subplots_adjust(top=0.90, bottom=0.05, wspace=0.90, hspace=0.3)
plt.show()
# تحميل مجموعة بيانات 20 newsgroups وتحويلها إلى ناقلات. نستخدم بعض الخوارزميات
# لتصفية المصطلحات عديمة الفائدة في وقت مبكر: يتم إزالة المنشورات من الرؤوس،
# الأقدام والردود المقتبسة، والكلمات الإنجليزية الشائعة، والكلمات التي تحدث في
# وثيقة واحدة فقط أو في 95٪ على الأقل من الوثائق.
print("تحميل مجموعة البيانات...")
t0 = time()
data, _ = fetch_20newsgroups(
shuffle=True,
random_state=1,
remove=("headers", "footers", "quotes"),
return_X_y=True,
)
data_samples = data[:n_samples]
print("تم في %0.3fs." % (time() - t0))
# استخدام ميزات tf-idf لـ NMF.
print("استخراج ميزات tf-idf لـ NMF...")
tfidf_vectorizer = TfidfVectorizer(
max_df=0.95, min_df=2, max_features=n_features, stop_words="english"
)
t0 = time()
tfidf = tfidf_vectorizer.fit_transform(data_samples)
print("تم في %0.3fs." % (time() - t0))
# استخدام ميزات tf (عدد المصطلحات الخام) لـ LDA.
print("استخراج ميزات tf لـ LDA...")
tf_vectorizer = CountVectorizer(
max_df=0.95, min_df=2, max_features=n_features, stop_words="english"
)
t0 = time()
tf = tf_vectorizer.fit_transform(data_samples)
print("تم في %0.3fs." % (time() - t0))
print()
# ملاءمة نموذج NMF
print(
"ملاءمة نموذج NMF (معيار فروبينيوس) مع ميزات tf-idf، "
"n_samples=%d و n_features=%d..." % (n_samples, n_features)
)
t0 = time()
nmf = NMF(
n_components=n_components,
random_state=1,
init=init,
beta_loss="frobenius",
alpha_W=0.00005,
alpha_H=0.00005,
l1_ratio=1,
).fit(tfidf)
print("تم في %0.3fs." % (time() - t0))
tfidf_feature_names = tfidf_vectorizer.get_feature_names_out()
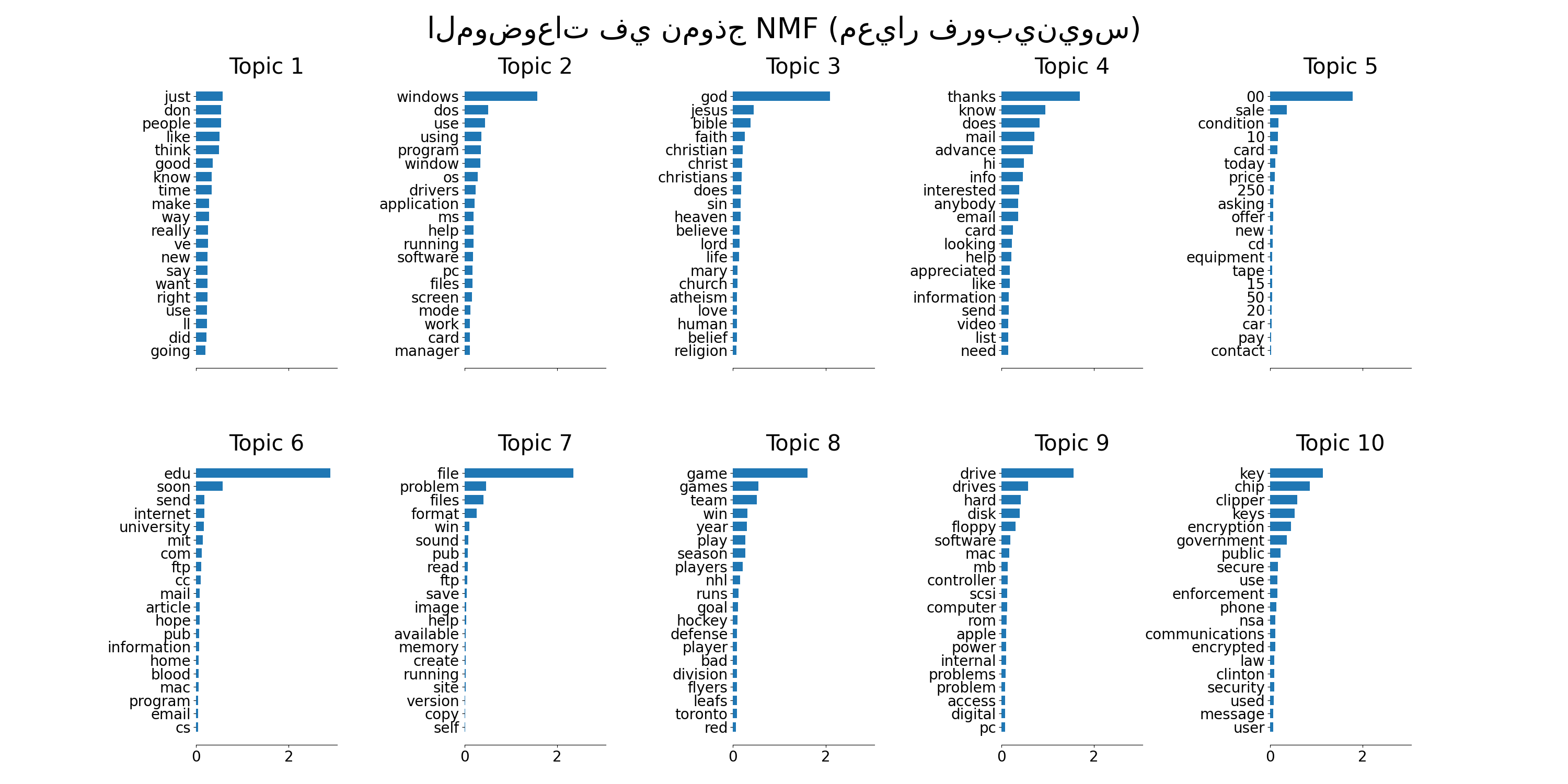
plot_top_words(
nmf, tfidf_feature_names, n_top_words, "الموضوعات في نموذج NMF (معيار فروبينيوس)"
)
tfidf_feature_names = tfidf_vectorizer.get_feature_names_out()
plot_top_words(
nmf, tfidf_feature_names, n_top_words, "الموضوعات في نموذج NMF (معيار فروبينيوس)"
)
# ملاءمة نموذج NMF
print(
"\n" * 2,
"ملاءمة نموذج NMF (التباعد العام لكولباك-لايبلر) مع ميزات tf-idf، "
"n_samples=%d و n_features=%d..." % (n_samples, n_features),
)
t0 = time()
nmf = NMF(
n_components=n_components,
random_state=1,
init=init,
beta_loss="kullback-leibler",
solver="mu",
max_iter=1000,
alpha_W=0.00005,
alpha_H=0.00005,
l1_ratio=0.5,
).fit(tfidf)
print("تم في %0.3fs." % (time() - t0))
tfidf_feature_names = tfidf_vectorizer.get_feature_names_out()
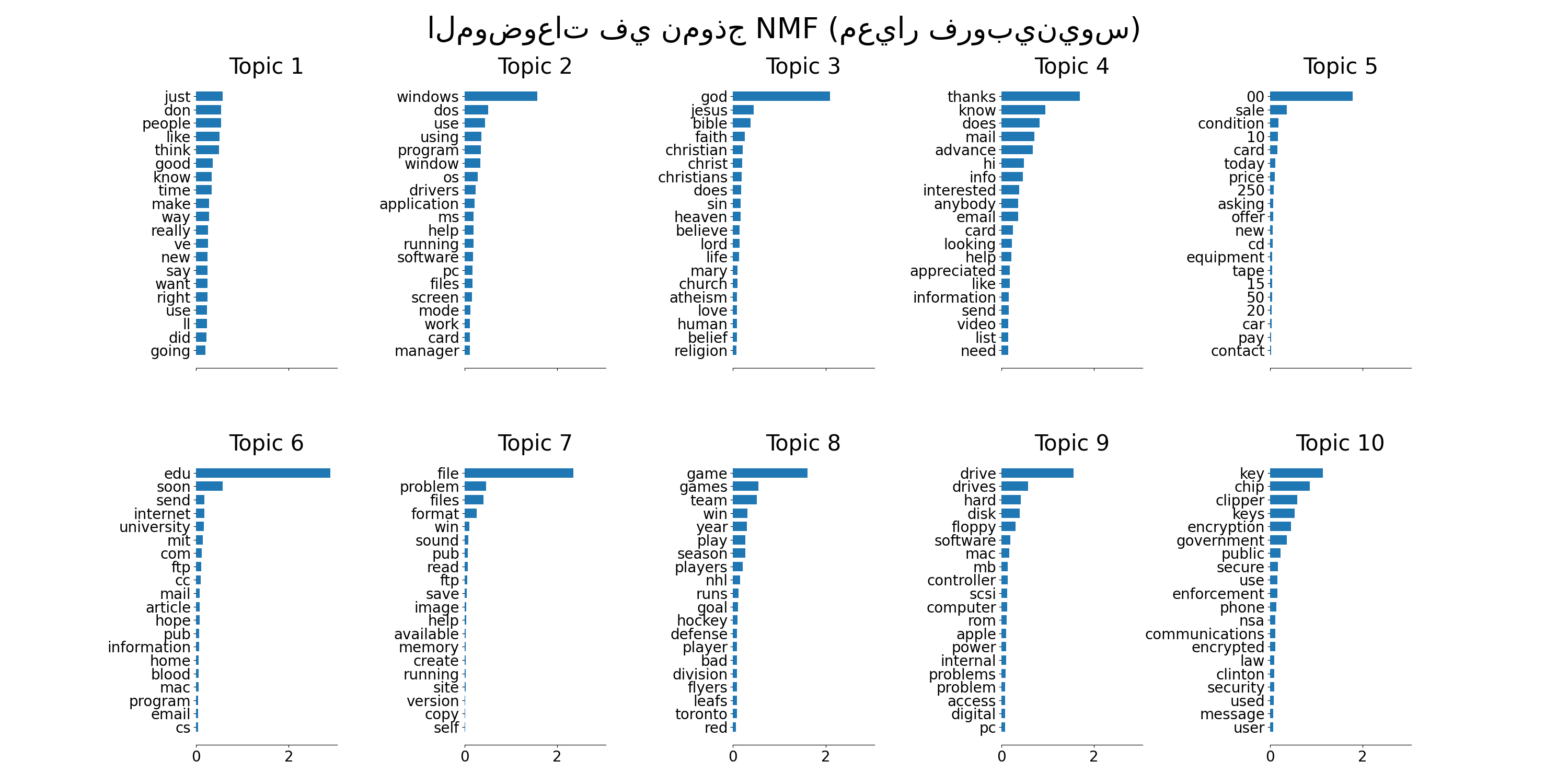
plot_top_words(
nmf,
tfidf_feature_names,
n_top_words,
"الموضوعات في نموذج NMF (التباعد العام لكولباك-لايبلر)",
)
# ملاءمة نموذج MiniBatchNMF
print(
"\n" * 2,
"ملاءمة نموذج MiniBatchNMF (معيار فروبينيوس) مع ميزات tf-idf "
"n_samples=%d و n_features=%d، batch_size=%d..."
% (n_samples, n_features, batch_size),
)
t0 = time()
mbnmf = MiniBatchNMF(
n_components=n_components,
random_state=1,
batch_size=batch_size,
init=init,
beta_loss="frobenius",
alpha_W=0.00005,
alpha_H=0.00005,
l1_ratio=0.5,
).fit(tfidf)
print("تم في %0.3fs." % (time() - t0))
tfidf_feature_names = tfidf_vectorizer.get_feature_names_out()
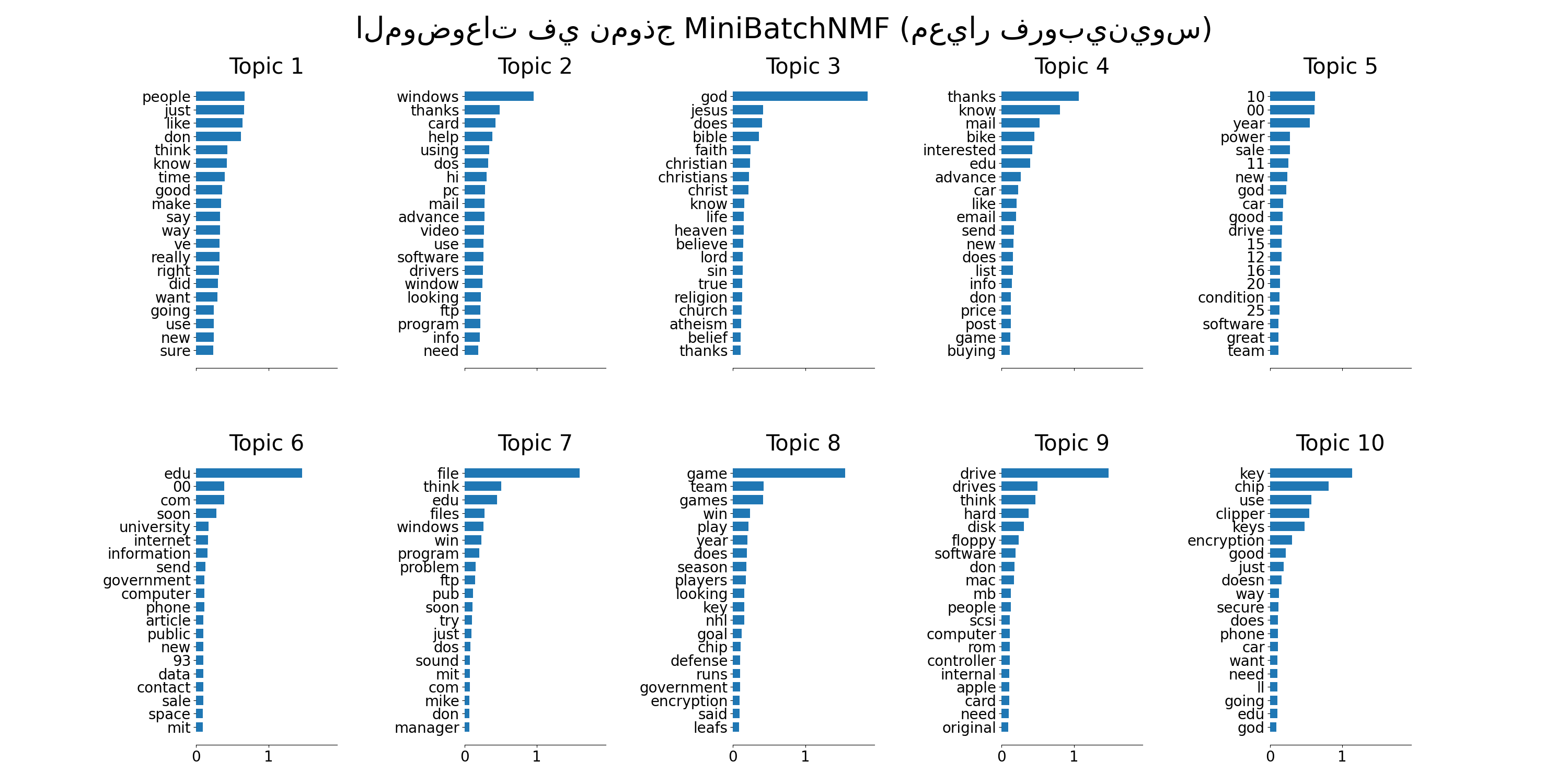
plot_top_words(
mbnmf,
tfidf_feature_names,
n_top_words,
"الموضوعات في نموذج MiniBatchNMF (معيار فروبينيوس)",
)
# ملاءمة نموذج MiniBatchNMF
print(
"\n" * 2,
"ملاءمة نموذج MiniBatchNMF (التباعد العام لكولباك-لايبلر) مع ميزات tf-idf، "
"n_samples=%d و n_features=%d، batch_size=%d..."
% (n_samples, n_features, batch_size),
)
t0 = time()
mbnmf = MiniBatchNMF(
n_components=n_components,
random_state=1,
batch_size=batch_size,
init=init,
beta_loss="kullback-leibler",
alpha_W=0.00005,
alpha_H=0.00005,
l1_ratio=0.5,
).fit(tfidf)
print("تم في %0.3fs." % (time() - t0))
tfidf_feature_names = tfidf_vectorizer.get_feature_names_out()
plot_top_words(
mbnmf,
tfidf_feature_names,
n_top_words,
"الموضوعات في نموذج MiniBatchNMF (التباعد العام لكولباك-لايبلر)",
)
print(
"\n" * 2,
"ملاءمة نماذج LDA مع ميزات tf، n_samples=%d و n_features=%d..."
% (n_samples, n_features),
)
lda = LatentDirichletAllocation(
n_components=n_components,
max_iter=5,
learning_method="online",
learning_offset=50.0,
random_state=0,
)
t0 = time()
lda.fit(tf)
print("تم في %0.3fs." % (time() - t0))
tf_feature_names = tf_vectorizer.get_feature_names_out()
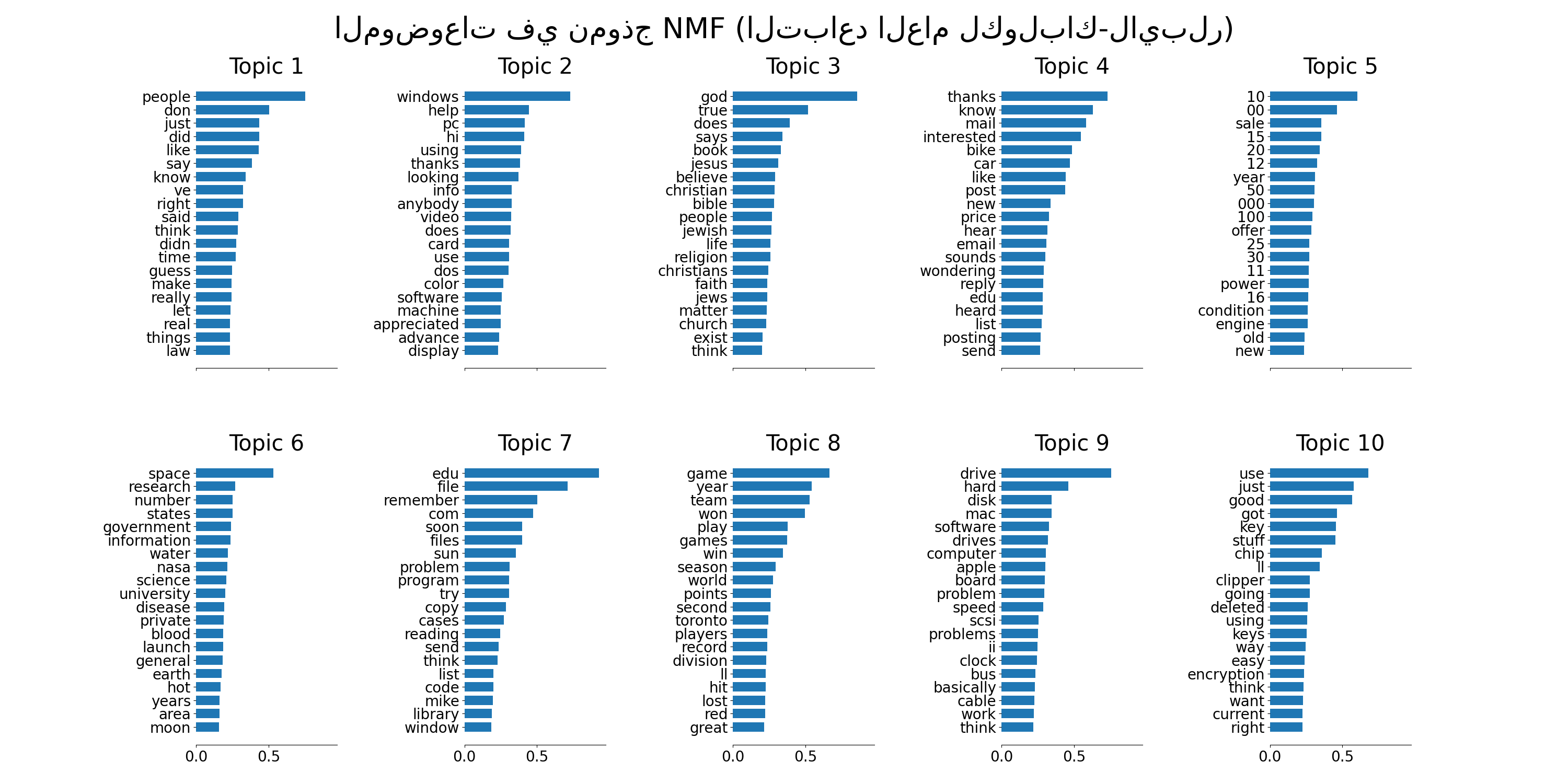
plot_top_words(lda, tf_feature_names, n_top_words, "الموضوعات في نموذج LDA")
Total running time of the script: (0 minutes 16.376 seconds)
Related examples
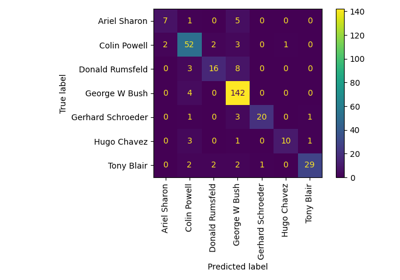
مثال على التعرف على الوجوه باستخدام الوجوه المميزة وآلات المتجهات الداعمة

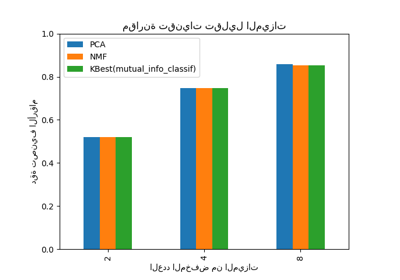
اختيار تقليل الأبعاد باستخدام Pipeline و GridSearchCV